Now that title is a hand full.
In the last post I looked at rendering UI rectangles with OpenGL 4.5.
The next step on that journey is text rendering, more specifically subpixel font rendering.
So instead of rather boring rectangles we're now also throwing individual characters ("glyphs") at the screen. Way more interesting. :)
I wanted to look into subpixel font rendering for quite a while now, especially to test out dual source blending (where you can blend each subpixel individually).
In the end I think I found a pretty good sweet spot between complexity and quality and wanted to document that.
And of course I also went down some interesting rabit holes (e.g. gamma correction) with unexpected results.
It's suprisingly difficult to find hard or complete information on subpixel text rendering and as a result this post became rather… long.
This post isn't an introduction into font rendering. Rather it describes the steps necessary to get a good result in OpenGL and sometimes the stuff nobody talks about.
If you stumble over an unknown word (e.g. hinting or kerning) feel free to look them up. This post is way to massive as it is.
In case anyone asks because 4k displays and stuff: All (except one) of my displays are 1080p and 99.99…% of the text I read is horizontal.
Subpixel anti-aliased text is a lot more comfortable to read for me but that depends on your eye sight (a friend of mine can hardly tell the difference).
If you can't tell the difference: Just don't bother. But if you write UI software for others you might want to occasionally borrow someone elses eyeballs.
On mobile and tablets it's a different story and I don't really care much about it. Grayscale anti-aliasing seems good enough there and the subpixel layouts would drive you crazy anyway.
Ok, with all that out of the way some results first:
Click the buttons to switch between various images.
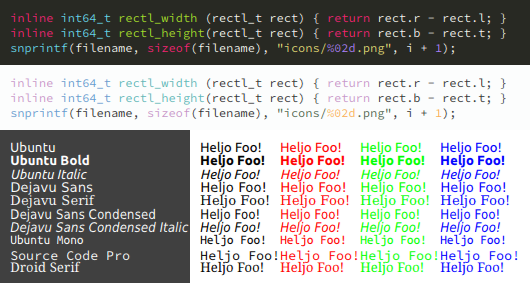
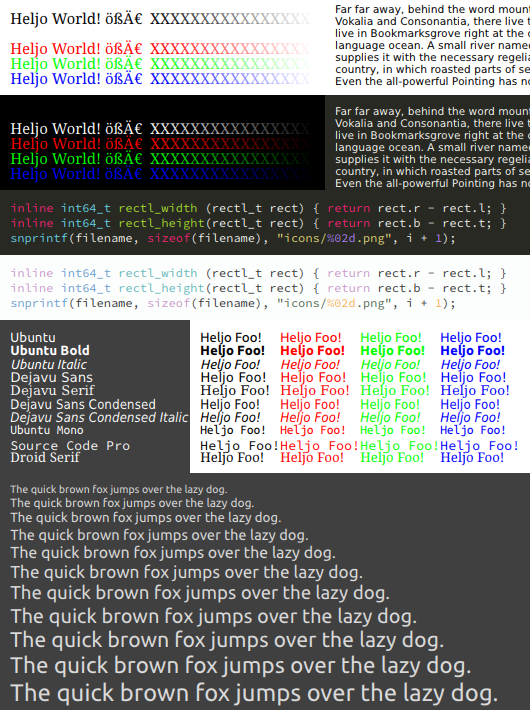
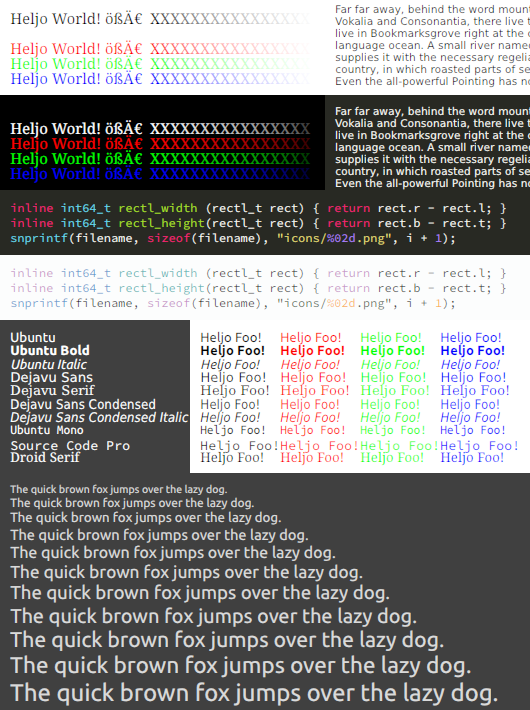
The first 4 images: Ubuntu and Dejavu Serif, rendered output vs. FreeType (via FontManager). I didn't bother to line up the exact line positions so they jump around a bit.
Text block: Dejavu Sans 8pt.
Text over image: Ubuntu Italic 12px from black to white with white to black 1px text shadow over "Haruhism - The Melancholy of Haruhi Suzumiya" (cycles through a lot of colors, useful to spot artifacts).
Only the first few and last few lines make sense, the rest is just gray text on a gray text shadow on top of an image.
Source code & fonts: Dark and light source code (Source Code Pro, Sublime Monokai & Breakers color schemes, 12px) and various different fonts at 10pt.
Increased weight: Same as before but with the subpixel coverages adjusted (linearly) for increased weight.

The quality is ok for the most part (at least for my eyes). Not perfect, not as sharp as it could be, but ok. Good enough for home-cooked UIs. But on smaller font sizes the hinting of FreeType clearly makes a big difference.
What it doesn't do:
- Hinting (nither vertical nor horizontal, and it shows)
- Different subpixel layouts (just standard RGB)
- Anything fancy with signed distance fields
- Ligatures
- Emojis or glyphs with multiple colors
- Variable fonts
- Fancy effects like text shadow
What it offers:
- Simpicity
- Can blend text over arbitrary background pixels (on top of images, for semi-transparent UIs, as a HUD in games, etc.)
- Just needs one texture atlas entry per glyph and font size (no need to store variants for subpixel shifts, background colors, etc.)
- No dependency on system librarys (Pango, DirectWrite, etc.)
- Only uses stb_truetype (self-contained single header library) for glyph rasterization
Still interested? Here's how it works (pretty images below):
- Rasterize the glyph with 3x the horizontal resolution using stb_truetype
- Apply the FreeType LCD filter to mitigate color fringes
- Upload the filtered glyph into an RGB texture atlas
- Do subpixel positioning while iterating over the glyphs and later in the shader
- Blend each subpixel individually with the framebuffer by using dual-source blending
- Optional: Adjust the subpixel coverages before blending to make the text a bit thinner or bolder
- Optional: I also use pre-multiplied alpha for the text color. Not really necessary here but makes life a lot easier once you have transparent borders, backgrounds, etc. and have to combine them.
Pretty much your run-of-the-mill texture atlas thing with just 3 subpixels in a pixel so to speak. Ok, maybe the LCD filter and subpixel positioning adds a bit extra, but that's it.
Each of the steps is explained in detail below, as well as a few interesting side quests (e.g. gamma correction), some future ideas and interesting references.
This will be a long one, here's a small table of contents to get around:
At that point I want to apologize: The blog was never designed to cope with posts as massive as this one. It might feel a bit cramped and endless. Sorry about that.
Demo program
A simplified demo program is available on GitHub.
It uses OpenGL 4.5 and is written for Linux and Windows (might work on MacOS, don't know).
The demo is pretty much just one large piece of code in the main() function that renders a given string.
The code is mostly meant as a reference in case you're interested in the nitty gritty details.
Hence no abstractions that you just have to crack open to see what exactly is going on.
It's probably a bit unusual and not "pretty" but you can slice the steps down later on however you want.
I'll directly link to the relevant pieces of code later on.
The project uses stb_truetype.h for glyph rasterization, mostly because it's simple and just one self-contained header file.
But it doesn't support hinting and that's the reason I don't do it. Otherwise I would probably do vertical hinting as mentioned in Higher Quality 2D Text Rendering by Nicolas P. Rougier.
Horizontal hinting is a more complex story, though.
After writing most of this post I remembered that rounding the font size to the nearest whole pixel can serve as poor vertical hinting (read that somewhere, not sure where).
I played around with that but it wasn't convincing. 8pt looked a bit better but other sizes sometimes worse. And I'm planning on using pixel font sizes instead of points anyway.
It wasn't worth redoing all the images so I tucked it in here. It won't be mentioned again in the rest of the post.
The texture atlas used by the demo is just a mockup that's horribly limited and inefficient.
But it's simple enough to not distract from the text rendering.
If you need a texture atlas you might want to look at Improving texture atlas allocation in WebRender by Nical for some ideas.
How it works
Before we go into each step I just wanted to show the effects and purpose of each one.
Use the buttons to flip through the effects of each step

- Subpixel resolution gives us more resolution (from ~100dpi to ~300dpi on 1080p displays). This makes the text sharper but causes color fringes.
- The FreeType LCD filter then exchanges some of that resolution to avoid most color fringes. It's basically a slight 1D blur.
- Subpixel positioning allows us to use the enhanced resolution to get rid of those uneven letter spacings. Especially visible in the name of the "Ubuntu Bold" font or in the light-on-dark text.
- Dual source blending then gets rid of those ugly fringy blending artifacts, especially on bright backgrounds. It helps sharpness and colors quite a bit, too.
All steps before just used the average of the subpixel coverages as alpha. There are way more complex ways to do this but it illustrates that there will be artifacts if you don't use dual source blending.
These images illustrates that you kind of need the whole set to get a good looking result without visible artifacts.
Maybe you can get away with skipping subpixel positioning, but reading that kind of text is annoying as heck. Sometimes a word just falls apart like "live" into "li" and "ve" above.
For me at least it boils down to: Do all of them or neither.
Only using pixel resolution at least looks sharp.
Subpixel resolution
I mention this step mostly for completeness and to avoid confusion.
Just rasterize the glyph as a "grayscale image" with 3 times the horizontal resolution, that's it (demo code).
That gives us a value between 0..255 for each subpixel.
Those values are linear coverages, 0 means the subpixel is 0% covered by the glyph, 128 means 50% covered and 255 means 100% covered.
A note on padding: The LCD filter below needs 1px padding to the left and right. Subpixel positioning might also shift the glyph almost 1px to the right, so we need another 1px padding to the left for that as well.
It makes sense to take that padding into account when you rasterize the glyph into a bitmap.
Then you don't have to move the glyph around after rasterization by doing error prone coordinate calculations and extensive bounds checking in the filtering step.
stb_truetype has subpixel functions as well. But these do a lot of what we do on the CPU and you can't really do a simple texture atlas thing with them. Also we don't need them since we have dual source blending. :)
FreeType LCD filter
Straight forward subpixel rendering can be a bit jaring for the eye. I hope the images above showed that.
All those subpixels do have a color and this causes the jaring color fringes.
The FreeType LCD filter is basically a slight horizontal blur. It distributes the brightness of one subpixel across neighboring subpixels (that have different colors) and thus gets rid of most color fringes.
To apply the filter you basically look from 2 subpixels to the left to two subpixels to the right (5 subpixels in total) and add up their value.
The further away a subpixel is from the current one the less it contributes to the sum (aka it's a weighted sum or a 1D kernel with 5 weights).
The filter weights are documented in the FreeType docs as FT_LCD_FILTER_DEFAULT: [0x08 0x4D 0x56 0x4D 0x08] in 1/256 units, or about [0.031, 0.302, 0.337, 0.302, 0.031].
Meaning the outermost subpixels contribute ~3%, our neighboring subpixels ~30% and out own subpixel ~34%. All adds up to 100% so a fully covered area stays 100% covered except at the fringes
(demo code).
A note on padding pixels again: Just add 1px padding at the left and right side.
The filter is 5 subpixels wide, so the subpixels at the edge of a glyph can distribute their values at max 2 subpixels into that left and right padding.
Hence the 1px (3 subpixel) horizontal padding.
The subpixel positioning step below also adds 1px padding at the left (comming up right below).
I also recommend to use the same bitmap size for glyph rasterization and filtering.
Then you can skip error prone coordinate calculations and extensive bounds checking.
It makes the filtering code a lot simpler even if the bitmap for glyph rasterization is a few (3) pixels wider than necessary.
At first I did the filtering in place until I realized that the filter then reads its own output of the previous subpixels (late-night coding…).
That distorts the brightness of the text a bit but at least to me it wasn't really noticable.
Instead the filter should read from the glyph bitmap and writes the filtered output into a 2nd bitmap.
Anyway, if you really want to you can probably get away with just using one bitmap and do the filtering in-place.
Here is a small comparison and diff.
The difference between filtering in-place and into a 2nd bitmap. Play spot the difference or look at the diff if you can't. The diff was created using GIMPs "Difference" blend mode.
Subpixel positioning
Subpixel positioning is relevant in two places:
When iterating over all the characters (glyphs) and calculating the rectangle positions for each one.
Just don't round there.
Use a float to keep track of the current x position, for advancing from glyph to glyph and when doing kerning (kerning in the demo code).
When calculating the glyphs rectangle position you can round down the x coordinate and send the remaining fraction (between 0…1) off to the shader (aka the subpixel shift in the demo code).
The fragment shader then takes the subpixel shift and, well, shifts the glyph coverages by that amount to the right.
This is done with a linear interpolation between neighboring subpixels (demo code).
Technically this means we can shift a glyph by fractions much smaller than a subpixel.
But at some point no one can tell the difference anyway.
I found this in the paper Higher Quality 2D Text Rendering by Nicolas P. Rougier which even contains the GLSL code for it (section "2.3. Subpixel Positioning").
The paper also has a small section (and nice image) on kerning if you want to read up on that.
You might notice that the GLSL shader code looks like it shifts the subpixels to the left. For whatever reason this confused me in this context but it's just a matter of perspective.
To shift something to the right on the screen a pixel at a fixed position has to show data to the left of itself. It's the same way with texture coordinates and a lot of other stuff in fragment shaders.
That's also the reason why we need an extra 1px padding to the left. The first pixel might look almost 1px to the left of itself and we don't want it to access anyone elses pixels.
You can also do the position calculations on the CPU in font units (ints) if you like. But a float will do. Even at 8k you still have a precision of 0.001 (a 1000th of a pixel).
No fancy images this time. The images in How it works already show the effect pretty well.
Subpixel blending aka dual-source blending
Now we're probably getting to the star of the show.
Usual alpha blending works with one blend weight per pixel (alpha) to blend the fragment shader output with the contents of the framebuffer.
But with dual-source blending we can give the hardware one blend weight per component. Meaning we can blend each subpixel individually. :)
With that we can directly use the subpixel coverages we get from the subpixel positioning.
Just blend each subpixel of the text color on top of the framebuffer with its own weight.
That's it. No magic involved.
Relevant demo code:
Setup in OpenGL,
setup in shader and
setting the blend weights.
It's core in "desktop" OpenGL since 3.3. For mobile systems GL_EXT_shader_framebuffer_fetch might be worth a look if you feel adventurous.
Unfortunately almost nobody mentions dual-source blending in regards to subpixel text rendering.
I found it here quite a few years ago and had it on my "I have to try this!" list ever since. Only took me 5 years or so to finally get around to it. :D
The OpenGL wiki also cover is reasonably well (here and here).
Basically you have to define another output for the blend weights and then tell the blend function to use those weights (switching from SRC_ALPHA to SRC1_COLOR):
// Fragment shader
layout(location = 0, index = 0) out vec4 fragment_color;
layout(location = 0, index = 1) out vec4 blend_weights;
// OpenGL setup for "normal" alpha blending (no pre-multiplied alpha)
glBlendFunc(GL_SRC1_COLOR, GL_ONE_MINUS_SRC1_COLOR);
// Or for pre-multiplied alpha (see below)
glBlendFunc(GL_ONE, GL_ONE_MINUS_SRC1_COLOR);
Again no fancy pictures. Jump back to How it works to satisfy your visual cravings.
But on the bright side: With this step you're done! The rest of this post is purely optional and informative (and maybe entertaining).
Optional: Coverage adjustment for a thinner or bolder look
In some situations you might want a bolder look (e.g. for a bit more contrast in colored source code) or a thinner look (e.g. black on white in some fonts).
This time there are fancy picture again. Lots of them actually. :)
Maybe first think about different usecases (terminal, notes, code editor, game UI, etc.) and then try to look for the most pleasent option for each one.
Effects of various ways of coverage adjustment to get a thinner or bolder look.
First image: Unmodified coverages.
Linear: Linear modification of coverages, positive = bolder, negative = thinner.
Exponent: pow() function (coverageexponent), < 1 is bolder, > 1 is thinner.
I hope you picked your favourite. :) If so maybe let me know via a comment at the end of the post.
How is it done? Well, the gradient from the outside of a glyph to the inside is maybe 2 to 3 subpixels wide.
1 subpixel from the rasterizration with 3x horizontal resolution. The FreeType LCD filter then blurs that to 2 or maybe 3 subpixels.
For me at least this was easier to understand with a bit of sketching:
Sketch of coverage values along the X-axis, from the outside of the glyph (coverage 0) to the inside (coverage 1.0). Subpixels are marked for scale on the X-axis.
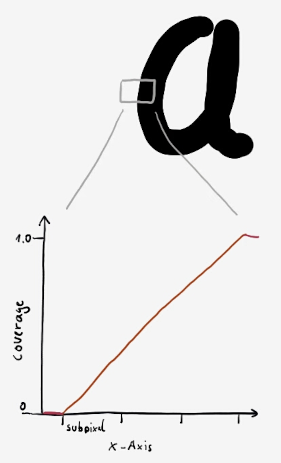
This isn't how it really looks. The FreeType LCD filter blurs it so it's more of a soft transition. But I found it easier to reason about it this way.
So far I've come up with the above two approaches to distort that gradient line a bit: Via an exponent or via a linear modification of the gradients slope.
Coverage adjustment via an exponent
Coverage values along the X-axis when distorted by a power function (coverageexponent).
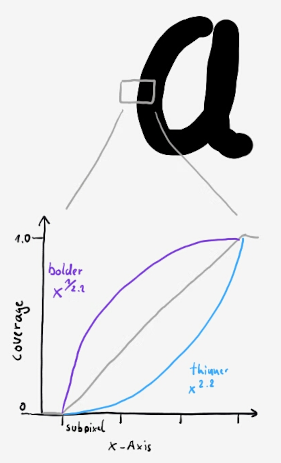
The sketch overemphasizes a bit for melodramatic effect by using an exponent of ~2.2.
If you throw it in a graph plotter and look at x1.43 the effect is much more subtle.
In GLSL code this simply is:
pixel_coverages = pow(pixel_coverages, vec3(coverage_adjustment))
Where pixel_coverages is a vec3 of the subpixel coverages along the x-axis, basically our subpixel values after subpixel positioning is done.
If coverage_adjustment is 1.43 the font becomes thinner (like the lower curve), if it's 0.70 (or 1/1.43) it becomes bolder (like the upper curve).
You can flip the effect with 1 / coverage_adjustment, e.g. to do thinning by the same amount you previously did thickening and vice versa.
A value of 1.0 does nothing.
I've included it in the demos fragment shader but it's commented out there in favor of the next approach.
To some of you this might look eerily familiar, and yes, this came out of the gamma correction rabit hole (more about that later).
Basically I wanted to understand what the hell "gamma-correct" blending with a gamma of 1.43 actually does, because it doesn't do gamma correction.
And after a lot of head-scratching, experiments and color-space stuff I think that this outline distortion effect is probably what most people are after when they do that "gamma-correct" blending with a gamma of 1.43.
Btw. blending in that 1.43 thing color space unbalances light and dark fonts a bit (black on white becomes a thinner while white on black becomes bolder).
We don't have that problem here since we're only adjusting the coverages and don't do any fancy distorted blending.
I intentionally called it "coverage adjustment" to make clear that this isn't gamma correction.
Linear coverage adjustment
After I finally understood what as actually happening (hopefully) I came up with another approach: Simply change the slope of the gradient.
Changing the gradient slope. Left side: Steeper slope with reference point at 0 coverage (appears bolder).
Right side: Steeper slope with reference point at 1.0 coverage (appears thinner), including steps of the calculation.
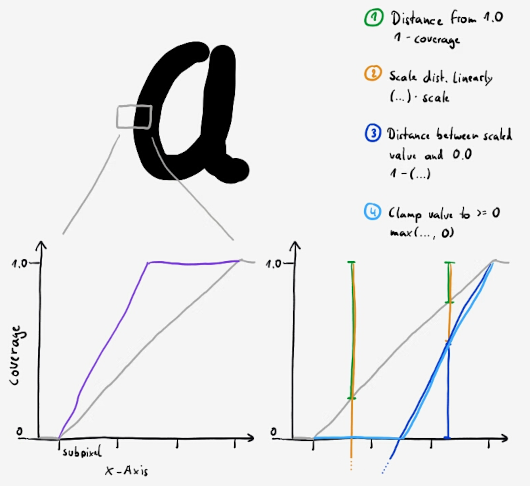
Additionally I built it so that positive coverage_adjustment values go into the left case (bolder) and negative values to into the right case (thinner).
For +1.2 this gives us a slightly bolder appearance. The gradient lines slop changes from 1.0 to 1.2, reference point at 0 coverage.
For -1.2 we get a slightly thinner one. The slope changes from 1.0 to 1.2 again, but with 1.0 coverage as reference point.
But anything between -1.0 .. 1.0 doesn't make much sense that way.
So we take that out and do slope = 1 + coverage_adjustment instead. Meaning +0.2 becomes a slope of 1.2 (bolder), 0 becomes a slope of 1 (does nothing) and -0.2 becomes a slope of -1.2 (thinner).
And this finally is our linear coverage adjustment value, the +0.20, etc. you saw above.
I've choosen the value range that way so it's easy to interpolate (e.g. based on the font size).
In GLSL it looks like this:
if (coverage_adjustment >= 0) {
pixel_coverages = min(pixel_coverages * (1 + coverage_adjustment), 1);
} else {
pixel_coverages = max((1 - (1 - pixel_coverages) * (1 + -coverage_adjustment)), 0);
}
The min() and max() just make sure that the output stays in the range 0..1.
That version is in the demo code as well, but coverage_adjustment is set to 0 (do nothing) by default.
In case you're allergic to if statements in your shaders, here is a branchless version. No idea if it's faster or slower, though.
// cond is 1 for negative coverage_adjust_linear values, 0 otherwise.
// Couldn't think of a good name.
float cond = float(coverage_adjust_linear < 0);
float slope = 1 + abs(coverage_adjust_linear);
pixel_coverage = clamp(cond - (cond - pixel_coverage) * slope, 0, 1);
So which approach to use?
I don't know.
In my experiments so far the linear coverage adjustment tends to be sharper and it's probably faster as well.
But on the other hand the pow() approach makes a softer falloff that maybe gives a bit better anti-aliasing.
I have to use this for a while to actually come to a conclusion about that.
My current plan is to use no coverage adjustment by default, except for colored source code. There I'm planning to use the linear coverage adjustment with +0.2.
You can send it along as a vertex attribute (or rather per rectangle attribute) instead of a uniform so each glyph can do it's own thing.
Then you can select what you need for the occasion while everything still (usually) happens in one draw call.
Maybe I can use linear +0.2 or even +0.4 as a very poor hinting hack for small font sizes like 8pt?
Start at 10pt with +0 and then scale it up to +0.4 at 6pt or so? No idea, more testing is needed (think that though in a GLaDOS voice if you want).
Another note:
By distorting the outline we're reducing the range where we're actually doing anti-aliasing.
If you overdo it the font will look less and less smooth and more and more jagged.
Small font features might even vanish if they don't have a fully filled subpixel in them.
But even with those caveats it can make text quite a bit more readable in some situations.
Optional: Pre-multiplied alpha
This part isn't really necessary for text rendering so if you're here just for the text rendering feel free to skip it.
Pre-multiplied alpha becomes very useful as soon as stuff in your UI can get transparent (backgrounds, borders, text, etc.).
Then you have to blend transparent stuff on top of each other within the shader and normal alpha blending kinda breaks apart at that point.
I stumbled upon the topic while figuring out how to properly blend transparent borders on top of a transparent background color.
After a lot of hit-and-miss I finally found the W3C Compositing and Blending Level 1 spec.
More specifically in section 5.1. Simple alpha compositing it spells out the formulas for alpha compositing:
The formula for simple alpha compositing is
co = Cs x αs + Cb x αb x (1 - αs)
Where
co: the premultiplied pixel value after compositing
Cs: the color value of the source graphic element being composited
αs: the alpha value of the source graphic element being composited
Cb: the color value of the backdrop
αb: the alpha value of the backdrop
The formula for the resultant alpha of the composite is
αo = αs + αb x (1 - αs)
Where
αo: the alpha value of the composite
αs: the alpha value of the graphic element being composited
αb: the alpha value of the backdrop
If you know your blend equations you will have noticed that the destination term (aka backdrop) contains two multiplications instead of just one: Cb x αb x (1 - αs).
The hardware blender can't do that. Or at least OpenGL doesn't provide the blend equations for that as far as I know.
And here the pre-multiplied alpha trick comes in handy: Just multiply the RGB components of a color with the alpha value before blending:
Often, it can be more efficient to store a pre-multiplied value for the color and opacity. The pre-multiplied value is given by
cs = Cs x αs
with
cs: the pre-multiplied value
Cs: the color value
αs: the alpha value
Thus the formula for simple alpha compositing using pre-multiplied values becomes
co = cs + cb x (1 - αs)
And that's why the blend function above was set to glBlendFunc(GL_ONE, GL_ONE_MINUS_SRC1_COLOR).
The demo converts the text color to pre-multiplied alpha in the vertex shader.
Pre-multiplied alpha has a lot of nice properties and uses, especially in gaming (e.g. mipmaps don't cause color artifacts).
Alan Wolfe wrote a good (and short) summary on StackExchange.
And What is Premultiplied Alpha? A Primer for Artists by David Hart shows quite nicely the effects of pre-multiplication as masking.
The post contains nice pictures and gives you a good intuitive understanding of how to use pre-multiplied alpha for compositing.
No need to repeat all that here.
A note on the API and implementation, though:
I only use 8 bit straight alpha colors (aka not pre-multiplied) in the entire API and for all CPU-side code.
This keeps the API simpler and a lot less confusing.
The vertex shader then converts those to pre-multiplied alpha.
In the vertex shader the colors are float vectors (vec4) and we don't lose precision if the multiplication happens there.
Doing the pre-multiply on the CPU with 8 bit ints probably would looses a lot of precision and might cause banding artifacts in dark regions.
Never really tested that though, so it might be a bit over-the-top.
For images (icons, etc.) I do the pre-multiplication in the fragment shader after the texture read.
You could do the pre-multiplication once on the CPU (with the same potential problems as above) but one multiplication in the shader doesn't kill me.
On mobile you might think differently.
Paths not taken
As I became a more experienced programmer I realized more and more that the things you don't do are actually way more important than the things you do.
It's oh so easy to build a complex mess of stuff that becomes magical simply because nobody understands it anymore.
But building something that does the job good enough and where everybody thinks "well, that's easy, how about adding X?". Well, that is hard.
Programmers (and many other disciplins) don't talk nearly enough about that.
So here I do and hopefully fewer people have to walk the same paths in vain, repeating the exact same errors for the exact same wrong reasons.
Paths not taken: The gamma correction rabit hole
If you read about subpixel text rendering you'll pretty quickly stumble upon gamma-correction.
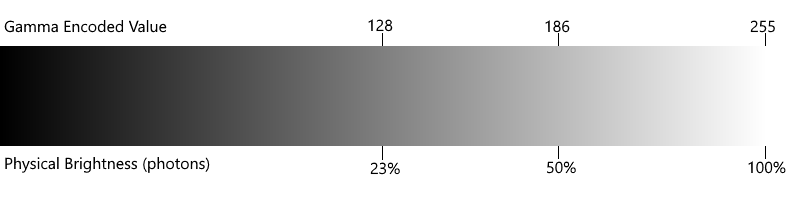
What is it? Stewart Lynch from PureDev Software has a good introduction for programmers: Gamma Encoding.
In a nutshell: "The brain can distinguish more dark shades than light [shades]".
Instead of directly storing the brightness of each color channel in normal RGB colors the values are distorted a bit towards darker shades.
With 8 bit integers this gives us a lot more values for darker shades, and for our perception this is where it counts.
Figure 1 from Stewart Lynchs article: "Shows how brightness values are encoded into 8 bits (0 – 255)"
A word about naming and nomenclature here. Various posts use various names for the different color spaces but here I'll stick to those two:
- Peceptual sRGB aka: "normal" RGB colors, gamma-encoded values, "encoded", "in sRGB colorspace", "RGB (perceptual)" in GIMP
- Linear sRGB aka: linear colors, decoded values, "in linear colorspace", "RGB (linear)" in GIMP
Peceptual sRGB colors are your standard run-of-the-mill RGB values you see everywhere. Doubling a value gives you something that looks twice as bright to our human eyes (well, somewhat).
With linear sRGB doubling the value doubles the amount of physical brightness (photons) that reach your eyes. Doesn't necessary look like that to us humans, see the above image.
But when you calculate light intensities in 3D games this is what you want to work with.
You can translate between the two color spaces with a "transfer function" (fancy name):
linear_srgb_color = perceptual_srgb_color ^ 2.2
perceptual_srgb_color = linear_srgb_color ^ (1/2.2)
Here 2.2 is "gamma" or "γ". And when you do stuff with linear sRGB colors it's usually called "gamma correction".
Note: This is a simplified transfer function that works most of the time.
The official function is a bit more complicated but the results are nearly the same, so most don't care.
But when you use OpenGLs sRGB support you should also use the official one or dark shades get distored, see below.
Blending artifacts in perceptual sRGB
John Novak wrote a pretty good article that shows the effects of gamma correction pretty nicely: What every coder should know about gamma.
In there he makes a pretty good point that blending two peceptual sRGB colors causes some artifacts.
Figure 8 from John Novaks article: "Effects of gamma-incorrect colour blending.
On the left gamma-correct image, the option Blend RGB Colors Using Gamma 1.0 was enabled in Photoshop CS6, on the right it was disabled (that’s the default gamma-incorrect legacy mode)."

Doing the blending with linear sRGB colors instead avoids those artifacts but often results in a brighter look.
A linear color space is really important in computer graphics where you actually calculate light intensities and stuff.
Not using linear sRGB can really mess things up there and ruin your weekend (or rather many weekends) so it's a rather sensitive topic for some.
Applying that to font rendering
Ok, but back to font rendering now. After reading all this my reasoning was:
We have a coverage value for each subpixel. A coverage of 50% means 50% of light comes through from the background.
So we should use our coverage values as light intensities and do the blending with linear sRGB colors, right?
But when you do subpixel font rendering and blend in linear sRGB this happens:
Effect of gamma correction on subpixel font rendering on two different examples.
Linear sRGB: Blending is done in linear space using OpenGLs GL_FRAMEBUFFER_SRGB. Input colors are converted with the official sRGB transfer function.
Perceptual sRGB: Blending in perceptual sRGB color space, aka alpha blending normal colors.
Gamma 1.43: Manual blending in the fragment shader with a set background color and a custom gamma of 1.43. Transparent text colors don't work here (never bothered to implement them in this mode).
Various scenarios:
Light to dark text:
Notice the unbalanced font weights in "linear sRGB" and "gamma 1.43"?
Black on white looks thinner while white on black looks almost bold.
The "light to dark text" example shows this especially well.
But this is the "correct" way, right? This led me on a merry chase to restore that black and white balance while still blending in linear sRGB color space.
Adjusting the blending weights based on the text- and/or background color in various (sometimes scary) ways, deriving (or number crunching) polynomials to nudge the blend equation in different directions, etc.
All very complicated, increasingly obsure and usually causing other artifacts that need a new set of workarounds.
Needless to say, at some point I just pulled the plug on that. After a few days that felt like crazy scientist experiments, that is. :D
What the Skia people say about this
Skia is the UI library used by Firefox and Chrome and they do a pretty good job of font rendering.
It's interesting what they say about the topic. Taken from The Raster Tragedy in Skia, emphasized the relevant part.
Note: "Linear blend function" means alpha blending here I think.
Skia does not convert into a linear space, apply the linear blend, and convert back to the encoded space. If the destination color space does not have a linear encoding this will lead to ‘incorrect’ blending. The idea is that there are essentially two kinds of users of Skia. First there are existing systems which are already using a non-linear encoding with a linear blend function. While the blend isn’t correct, these users generally don’t want anything to change due to expectations. Second there are those who want everything done correctly and they are willing to pay for a linearly encoded destination in which the linear blend function is correct.
For bi-level glyph rendering a pixel is either covered or not, so there are no coverage blending issues.
For regular full pixel partial coverage (anti-aliased) glyph rendering the user may or may not want correct linear blending. In most non-linear encodings, using the linear blend function tends to make black on white look slightly heavier, using the pixel grid as a kind of contrast and optical sizing enhancement. It does the opposite for white on black, often making such glyphs a bit under-covered. However, this fights the common issue of blooming where light on dark on many displays tends to appear thicker than dark on light. (The black not being fully black also contributes.) If the pixels are small enough and there is proper optical sizing and perhaps anti-aliased drop out control (these latter two achieved either manually with proper font selection or ‘opsz’, automatically, or through hinting) then correct linear blending tends to look great. Otherwise black on white text tends to (correctly) get really anemic looking at small sizes. So correct blending of glyph masks here should be left up to the user of Skia. If they’re really sophisticated and already tackled these issues then they may want linear blending of the glyphs for best effect. Otherwise the glyphs should just keep looking like they used to look due to expectations.
For subpixel partial coverage (subpixel anti-aliased) glyph masks linear blending in a linear encoding is more or less required to avoid color fringing effects. The intensity of the subpixels is being directly exploited so needs to be carefully controlled. The subpixels tend to alleviate the issues with no full coverage (though still problematic if blitting text in one of the display’s primaries). One will still want optical sizing since the glyphs will still look somewhat too light when scaled down linearly.
How I interpret this: If you don't go all in and do "proper optical sizing and perhaps anti-aliased drop out control" don't blend in the linear sRGB color space.
The 2nd part is interesting, though. I'm doing subpixel anti-aliasing here but the color fringes are pretty much gone. My guess is that this part referes to subpixel anti-aliasing with full-pixel alpha blending. There the color fringes are a lot harder to fight. You can see this in the "Subpixel pos." image back in How it works.
Well, this whole project is about a sweetspot between quality and simplicity, so linear sRGB isn't the right tool for the job here.
Perceptual sRGB colors just do a better job in our situation with less artifacts. At least when combined with dual source blending.
Artifacts are still there, just less than with a linear sRGB color space.
Another way to look at it: Human perception of gradients
The perceptual and linear sRGB color spaces both have their problems.
Björn Ottosson wrote a nice post about that: How software gets color wrong.
Both color spaces have parts where they come close to human perception and parts where they fail, even if linear sRGB does better with most colors.
Of special interest however is the human perception of the black and white gradient because that kind of is what we blend between for black on white or white on black text.
Comparisons - White and black from Björn Ottossons article:
Perceptual blend: A smooth transition using a model designed to mimic human perception of color. The blending is done so that the perceived brightness and color varies smoothly and evenly.
Linear blend: A model for blending color based on how light behaves physically. [I call this linear sRGB in this post.] This type of blending can occur in many ways naturally, for example when colors are blended together by focus blur in a camera or when viewing a pattern of two colors at a distance.
sRGB blend: This is how colors would normally be blended in computer software, using sRGB to represent the colors. [Called perceptual sRGB in this post.]

With that gradient in mind the result of blending in linear sRGB becomes somewhat apparent:
In there almost all parts of the gradient are bright.
Now we apply that to the gradient at the outline of a glyph (inside 100%, outside 0%): Most of the outline will be the bright part of the gradient.
If the glyph is bright this will add to the area of the glyph, meaning it becomes bolder.
If the background is bright this will add area to the background, or put in another way removes the area from the dark glyph. Meaning it will become thinner.
That fits how blending in linear sRGB distorts black on white or white on black text.
Black to white gradients in perceptual sRGB are way closer to human perception, thus the fonts have a balanced font weight.
Maybe the results would be better if we do the blending in a more perceptually uniform color space.
Meaning a color space where "identical spatial distance between two colors equals identical amount of perceived color difference" (from the linked Wikipedia page).
Basically the "perceptual blend" above.
The Oklab color space by Björn Ottosson again seems an interesting candiate for that.
To be honest perceptual sRGB does a pretty good job already and we could only do custom blending in the fragment shader with a known background color anyway.
But I couldn't get it out of my head, so I did a quick test:
Effects of blending in the Oklab color space when doing subpixel font rendering.
Note that transparent colors are broken in both versions (again, didn't bother to implement that).
Oklab: Convert colors into Oklab, blend and convert back. Each component is blended individually which probably breaks something.
Perceptual sRGB: Manual per-channel alpha blend in perceptual sRGB color space.
Various scenarios:
Light to dark text:

So, yeah, that didn't work out. :D I guess it's better to not take that gradient metaphor to seriously.
But then, we're talking about subpixels here and I'm really not an expert on any of those topics.
Maybe that gradient thing is a good indicator of what's going on, maybe not. Color and brightness perception is a weired thing.
Take everything in this subsection with a grain of salt (or maybe with a whole pitcher of it).
Other (unintended) consequences
Blending in linear sRGB gives different results by design. Usually we want that… but sometimes we don't.
Effects of blending in the linear sRGB color space on not text rendering stuff for a change.
Use the buttons to switch between linear and perceptual to get an impression of the changes.
Colors: Text (top) and color (middle) blending tests inspired by images from John Novaks What every coder should know about gamma article.
The bottom part is a border and corner radius test I used for debugging.
Icons and images: Various image blending tests,
Aerial Photography of Rock Formation by Ian Beckley,
the icon for "C" files from GNOME Desktop icons (not sure it's from there)
and a blending test image from Eric Haines article PNG + sRGB + cutout/decal AA = problematic.
Colors:
Icons and images:
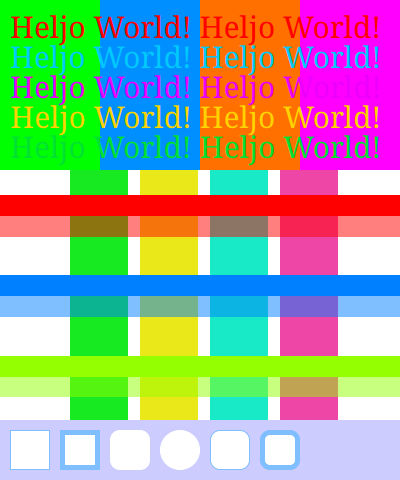
The "Colors" scenario reflects my experience with linear sRGB blending so far: Yay, some artifacts are gone (top), oh, the transparent colors look slightly different (middle), oh, the borders don't look like they should (bottom).
The border colors in the bottom part are a transparent blue. With perceptual sRGB blending this looks just as designed but linear sRGB blending results in a different color that's a lot closer to the overall background color.
Pretty unfortunate in this case.
But thats the kicker: If your artwork (color scheme, images, icons, …) are made for perceptual sRGB blending it will look off with linear sRGB blending (usually to bright).
And it seems most stuff is made for perceptual sRGB blending.
So if you do linear sRGB blending all the artwork has to be made for it as well.
It's not just about doing "correct" blending, you're literally blending differently and your artwork needs to reflect that.
"Icons and images" shows the same dilemma but with images: The shadow of the "C" icon is made for perceptual sRGB blending. With linear sRGB blending the shadow loses a lot of its function.
Small thing but can be suprisingly annoying.
The big image at the bottom is a pretty cool test image from Eric Haines article PNG + sRGB + cutout/decal AA = problematic.
It tests if blending is done according to the PNG spec. I've added two white rectangles behind the right side so I can see all relevant cases at once.
With linear sRGB blending it comes out correct (most of it is as bright as the 50% coverage) and with perceptual sRGB blending you get a different result (not matching the PNG spec).
Needless to say, most do perceptual sRGB blending (e.g. browsers).
Same dilemma: Blending and artwork have to match up, otherwise it looks off.
As long as everyone is doing (or assuming) the same thing (perceptual sRGB) it works out.
But as soon as some mix it up confusion ensues.
Bonus trick: In GIMP you can change how a layer is blended via its context menu. "Compositing Space" → "RGB (linear)" or "RGB (perceptual)". Nice to quickly check what looks right.
With GIMP 2.10.30 the default is "RGB (linear)" to blend layers on top of each other but I have no idea what happens when the alpha channel is exported (e.g. as a PNG).
That gamma 1.43 thing
I picked it up in Sub-Pixel, Gamma Correct Font Rendering by Stewart Lynch. It's also mentioned in John Novaks article as 1.42 and it seems to originate from a Photoshop text rendering feature. As the story goes fonts look to thin with gamma correction and a gamma of 2.2 so you use a gamma of 1.43 or so instead. Now they look as intended. Arguably because the fonts were designed for non-gamma-correct font rasterizers.
Personally I guess font renderers in the past did way more agressive hinting and fonts (as well as displays and resolutions) were generally smaller. Hence fonts were designed to compensate for that and generally bolder.
Anyway, I have no idea what Photoshop really did there.
Maybe they simply adjusted the coverages like my first approach above.
Or maybe they actually did blend in a color space with gamma 1.43. I don't know.
But blending in a color space with gamma 1.43 is neither perceptual sRGB nor linear sRGB.
At that point you're not correcting anything, you just blend in a weird mixed up color space that has less artifacts.
Light and dark fonts still become unbalanced, just not by as much (see the "light to dark text" gamma 1.43 image in Applying that to font rendering).
But this gave me an interesting idea:
From a math point of view multiplying a color with coverages in a color space with gamma 1.43 is the same as multiplying the color directly with the coverages^(1/1.43).
( color1.43 * coverages )1/1.43
= (color1.43)1/1.43 * coverages1/1.43
= color(1.43 * 1/1.43) * coverages1/1.43
= color1 * coverages1/1.43
= color * coverages1/1.43
And at some point that strange idea clicked with what that means of the coverages themselves (distorting the gradient at the glyph outline).
Hence the coverage adjustment was born and I left the blending alone (read I'm doing it in perceptual sRGB space).
And lo and behold, the results were finally uniform again between light and dark text.
Balance was restored. :)
And I could adjust the exponent for thinner or bolder looks and get predictable results across different situations.
Final gamma aside: OpenGLs sRGB support
By default OpenGL simply assumes linear behaviour and doesn't care about color spaces and such things.
If you feed perceptual sRGB colors into OpenGL it will do blending in that color space. If you feed it linear sRGB colors it blends in this space.
There is no magic happening behind your back.
But if you set it up carefully OpenGL will do most of the color conversions for you.
You can leave your image, texture and framebuffer data in perceptual sRGB but your shader can work in linear sRGB and the blending happens in linear sRGB as well.
Oh, and the conversions are hardware accellerated as well.
You just have to tell OpenGL what's what so it can do the work for you.
For textures: You can create textures with sRGB formats (e.g. GL_SRGB8_ALPHA8).
This tells OpenGL that the texture data is in the perceptual sRGB color space.
When you read the texture data in your shader OpenGL will now automatically convert the texture data to linear sRGB for you.
Just have to set the proper texture format, and thats that.
For framebuffers: With glEnable(GL_FRAMEBUFFER_SRGB) you tell OpenGL that your framebuffer is in the perceptual sRGB color space while your fragment shader outputs linear sRGB colors.
Blending is then done in linear sRGB color space: Read previous framebuffer value in perceptual sRGB, convert it to linear sRGB and then blend it with your fragment shader output.
After that the blend result is converted back to perceptual sRGB and written back to the framebuffer.
You might have to ask for an sRGB capable default framebuffer on window creation, though.
In SDL you can do this via SDL_GL_SetAttribute(SDL_GL_FRAMEBUFFER_SRGB_CAPABLE, 1).
Not all drivers seem to need that.
And you don't need that when you render into a frame- or renderbuffer of your own.
Just use an sRGB texture format for that buffer. Haven't done that in my experiments though.
For vertex shader inputs:
You have to manually convert colors you pass as uniforms or vertex attributes.
OpenGL doesn't know what vec4 is a color and which is a position or whatever, so it can't help you there.
But you have to do that with the high-precision gamma transfer function so your work lines up with what OpenGL does.
Often people just use pow(rgb, 2.2) and pow(rgb, 1/2.2) as transfer functions because they're simpler and are mostly good enough.
But here this leads to a missmatch: We convert our colors to linear sRGB with a different function than OpenGL uses to convert them back to perceptual sRGB later.
As a result darker shades get distorted a bit (starting at brightness ~120 and visible at ~16 or ~8).
Using the high-quality transform functions avoids the artifacts and everything lines up nicely between our code and OpenGL / the hardware.
I've implemented them in GLSL based on the linked Wikipedia page above. Finally a nice chance to use mix() to select via a bool vector. :)
vec3 color_srgb_to_linear(vec3 rgb) {
return mix( rgb / 12.92 , pow((rgb + 0.055) / 1.055, vec3(2.4)) , greaterThan(rgb, vec3(0.04045)) );
}
vec3 color_linear_to_srgb(vec3 rgb) {
return mix( 12.92 * rgb , 1.055 * pow(rgb, vec3(1 / 2.4)) - 0.055 , greaterThan(rgb, vec3(0.0031308)) );
}
And here is how it looks:
Effects of using the inaccurate gamma 2.2 sRGB transfer function with OpenGLs sRGB support.

Notice that between the official sRGB transfer function and the gamma 2.2 shortcut the text stays the same but the darker background colors on the right get even darker with 2.2.
If you then compare them both to the perceptual sRGB output you see that the background colors line up with the official sRGB transfer function but gamma 2.2 distorts the darker shades.
The EXT_framebuffer_sRGB extension also contains an approximation of the transfer function.
You might want to use that as well but I haven't tested it (only found it later).
It's probably an even closer match to what OpenGL does.
I thought this was pretty neat for UI work and I used it for some of the experiments shown above.
But it took some searching to assemble all the parts so I wanted to mention it all in one place.
Paths not taken: Manual blending with a known background color
In some situations the background color is known. For example when displaying source code we probably want to use the color schemes background color.
Then we can tell the fragment shader that background color and it can do any kind of blending it wants, just returning the final (non-transparent) color.
You can use this to implement gamma-correct blending even if everything else happens in perceptual sRGB (e.g. so the images and colors look like the artists expect).
Or you can do fancy stuff to enhance contrast between the text and background color.
I did a lot of fancy and scary experiments but in the end nothing was really convincing.
Blending in a linear sRGB color space caused more trouble than it fixed (see above) and the Oklab color space didn't help either.
Even if Oklab looks great for color gradients.
And remember: This only works on top of a known solid background color.
And I would really like to blend on top of images, a game or use transparent UI elements.
So I shelved the entire line of enquirey for now.
Just as an utterly over-the-top note:
If someone finds an exceptionally epic blending function for subpixel rendering and you really want that for everything you can use order-independent transparency.
For each pixel you first collect all the colors of e.g. the topmost 4 layers and then combine them in a dedicated resolve pass.
And in that resolve pass you have the colors for foreground and background and can blend them however you want.
Order-independent transparency is usually a thing in games to render transparent geometry when sorting doesn't work (or you don't wand to do it).
Christoph Kubisch describes that in his presentation Order Independent Transparency In OpenGL 4.x.
Specifically the "Atomic Loop 64-bit" approach looks pretty promissing.
We can abuse it for UIs if we really want to invest that complexity.
Insanely over-the-top for normal UI work so I thought I mention it.
If someone is insane enough to do that, please let me know. :)
Paths not taken: Dynamically choosing coverage adjustment based on text and background color
I did that mostly as a workaround for artifacts caused by various kinds of "gamma correction".
I experimented with a coverage adjustment based on the perceived brightness of the text color, based on the old HSP Color Model — Alternative to HSV (HSB) and HSL by Darel Rex Finley.
Oklabs L component might have been a better choice but I didn't know Oklab at that time.
It kinda worked anyway, but usually those workarounds just made one situation look good (e.g. colored source code) and caused artifacts in others (color bleeding, normal text becomming to bold, etc.).
Pretty much the same happened when I played around with a known background color or even the difference between the text color and the background color.
I found nothing that worked well in the general case.
And if the user knows about a special case (e.g. colored source code) they can simply set some special text rendering parameters (e.g. making the font slightly bolder with coverage adjustment).
So in the end I just settled on the coverage adjustments described above.
They're simple, relatively easy to understand and have a uniform result.
Ideas for the future
I still have a lot of interesting stuff bouncing around and here is a short list of the highlights.
Some of you probably think about simiar things right now (that is if someone ever arrives down here).
Signed distance fields for text shadows
I don't want to use them for normal text rendering because finding the right field size to avoid artifacts is pretty difficult.
But at the same time I want a diffuse shadow behind text to enhance the contrast above images. Speak: A blurry text shadow.
And for that signed distance fields should work just fine since fine details should become irrelevant anyway. sbt_truetype can generate them as well.
But I don't want to have a 50px signed distance field when someone requests a large blur radius.
Instead I'm planning to add just 2px padding or so outside of the glyph (filled with signed distances).
When someone needs a distance outside of that I'll just look for the closest pixels and approximate the distance based on the fields direction there.
With a bit of luck this should approximate the distance as a line (one outermost position) or a circle (two outermost poitions one pixel apart from one another).
No idea if that will work, though.
Signed distance fields might also be a nice fallback for very large font sizes.
If a glyph would be larger than e.g. 128px we can rasterize it as a signed distance field with a height of 128px and store that in an atlas texture.
Then user can zoom in as much as they want while we simply keep using that same 128px field all the time.
Sure, we still might lose some glyph detail for extreme fonts but it's probably simpler than writing an entire curve renderer for outlines.
Should also work well with subpixel positioning and dual source blending, but at those font sizes it's probably a moot point.
2x2 oversampling for animated text
Right now I only need horizontal text and it's not even animated.
But once I want animated text I'll try Font character oversampling for rendering from atlas textures from stb_truetype.
Basically just render the glyph with double the horizontal and vertical resolution and use linear interpolation.
Sounds neat and simple and fits in nicely with the grayscale atlas I'll need for signed distance fields anyway.
Use DirectWrite and Pango when available
This is very far in the future. Mostly I want them for complex text layout.
Pango provides an API for that and I've seen something about that in DirectWrite but I'm not sure if it's usable.
It would also provide automatic replacement glyphs in case a font doesn't offer a glyph.
I guess we would get a more authentic system look, too.
It's also a good point to take a closer look at horizontal hinting for small font sizes.
The 8pt output of FreeType looks pretty convincing to me and if they do horizontal hinting to achieve that so would I.
But it's probably tricky to pull off without derailing the texture atlas approach.
Maybe let FreeType do hinting on subpixel boundaries and then do something in the shader to nudge those boundaries to full pixel boundaries.
Or try to round the subpixel shift to full subpixels and see how that looks.
Do something useful when the background color is known
As a final part it still feels like you can do a lot more if the text and background colors are known.
I couldn't find anything that actually made things better, but that doesn't mean there is no such thing.
Granted, dual source blending probably eliminates the need for most tricks in that regard, but still… it feels like wasted potential.
Other approaches and interesting references
I'll mostly just link to other stuff here. Explaining it all would take the post even further past the endurance threshold. Anyway, Aras Pranckevičius wrote a pretty nice post in 2017: Font Rendering is Getting Interesting. It provides a good overview and has some pictures. It boils down to:
- Rasterize on the CPU (FreeType, stb_truetype, whatever) and cache the result in a texture atlas
- Put signed distance fields in the atlas so you can scale the glyph on the GPU and still get sharp glyph shapes
- Rasterize the glyphs directly on the GPU
The CPU rasterization and texture atlas approach is still the workhorse as far as I know.
FreeType, stb_truetype, DirectWrite, etc. do the rasterization and UIs like GTK then to the texture atlas thing. Same as I described in this post.
Pretty good quality but someone has to manage the texture atlas. It's the "classic" GPU assisted font rendering approach.
Distance fields are pretty useful if you have a lot of different text sizes floating around.
Or for animations and effects like shadows, outlines, etc.
But they lose small glyph details depending on the size of the distance field and in UIs their advantages don't weight that heavily.
But in games and espcially on 3D surfaces they're pretty awsome.
I stopped following that field a few years ago but back then multi-channel distance fields by Viktor Chlumský where the most advanced approach.
There you use RGB for 3 distance fields and combine them in the shader to better represent sharp features in glyphs.
Avoids a lot of artifacts and lets you get away with smaller field sizes.
Constructing the multi-channel field is rather complex, but fortunately described in detail in his masters thesis.
There are also approaches that rasterize the glyphs directly on the GPU. Aras blog post above lists a few.
As far as I can tell Slug by Eric Lengyel came out of that.
There you store the font description on the GPUs and each pixel looks at it to build the glyph. It's the first approach that actually convinced me.
The website also links a paper and slides with a lot of details about the algorithm.
But it's a bit to ambitious for a hobby project, even for my tastes.
Easy Scalable Text Rendering on the GPU by Evan Wallace also seems pretty interesting but requires a lot of triangles and overdraw per glyph.
It's neat, but not sure if that is worth it.
Apart from those low-level libraries and approaches there are of course libraries like Skia that do text rendering.
And Skia does a pretty good job of it.
They also have a very interesting design document where they talk about their font rendering: The Raster Tragedy in Skia that I quoted from above.
And this brings me to the The Raster Tragedy at Low-Resolution Revisited by Beat Stamm.
He worked on a lot of font rendering stuff at Microsoft, including ClearType.
The Raster Tragedy is a vast treasure trove and I still haven't finished reading it all.
But it focuses a lot on hinting as a tool to adjust fonts and I'm not that interested in the internals of glyph rasterization.
I'm leaning more towards the GPU side of things.
Interesting tidbit: As far as I can remember none of them mentioned subpixel blending aka dual source blending.
I wouldn't be surprised if Skia does it but I couldn't find any mention of it from them.
Also worth mentioning is FreeTypes Harmony LCD rendering as mentioned in their documentation.
It can handle different subpixel positions and is a pretty neat idea.
A note on something not strictly font-rendering related: stb_truetype is a small self-contained single header C file. No dependencies.
Skia is a huge project with a lot of dependencies and I don't event want to think about building it.
Depending on the project those aspects can be more important than quality (in my case they are).
The End
Phew! If anyone other than myself reads those last few words: You've just unlocked the endurance achievement, congrats. :)
I hope those mad ramblings were interesting or at least entertaining. And maybe they spared you a bit of pain and suffering.
If you have any related tidbits or ideas please drop a comment or send me a mail.
May all your glyphs look sharp enough.
Well, it happened again. I was just writing a UI system in C (different story) and thought about the performance of different ways to render rectangles. Most people would just look around a bit and choose a suitably impressive or "modern" approach and be done with it. Some would even research the topic for a bit and then choose the appropriate approach for their environment. Well, I did a bit of both, got distracted for a few weeks and somehow ended up with another small benchmark about UI rectangle rendering… I didn't do it on purpose! It just happened! Could happen to anybody, right? Ok… maybe there was a bit of purpose involved. :D
Aaanyway, most UIs today don't generate the pixels you see on screen directly. Instead they create a list of what needs to be drawn and then tell the GPU to do it. I wanted to know how long that GPU rendering part takes. Given the UI for a text editor, does it take 10ms, 1ms or 0.1ms? After all, everything before that point depends on how I choose to design the UI system. But I can't choose to create a graphical user interface that doesn't show anything. So that rendering part is my hard performance limit and I can't get faster than that.
TLDR: On a desktop system it takes between 1ms and 0.1ms to render a text editor UI with a lot of characters (6400 mostly small rects). At least when rendering is done using one large buffer for rectangle data and one draw call. ~1ms on low-end systems (AMD A10-7850K Radeon R7 and i7-8550U with UHD 620) and ~0.1ms on more decent GPUs (Radeon RX 480, Arc A770, GeForce GTX 1080).
Results (without context)
In case you just want to dive in, here are the results for a text editor and mediaplayer dummy UI. Those charts are huge, you have been warned:


Yes, you'll have to scroll around a lot. Those two images contain the measured times for different approaches (on the left) on different hardware (on the top).
I was also interested in how the different approaches compare to one another on the same hardware. Basically which approach I should use for my UI system. So here are the same diagrams but normalized to the one_ssbo_ext_one_sdf approach. Meaning that the values for one_ssbo_ext_one_sdf are always 1.0. But if e.g. the draw calls of ssbo_instr_list take 3 times longer on the GPU that bar would now show a 3.00. Note that the visual bars are capped at 5.0, otherwise the diagram would be mindbogglingly huge.


Please don't use the data to argue that one GPU is better than another. Rectangle rendering is a trivial usecase compared to games and the workload is very different. The first set of charts is there to get a rough feeling for how long it takes to render a UI, the second set of chars to compare the approaches with each other.
I've put the raw data and source code into a repository. Take a look if you want, but be warned, this is a hobby project. The code is pretty ugly and there's a lot of data. I don't get paid enough for that to think about how other programmers read the source code of my crazy experiments.
Context (aka what all that means)
My target systems were linux and windows desktops. No smartphones, no tables, no Macs. Mostly because developing for them is a pain and at that point I'm doing this for fun.
I used OpenGL 4.5 as an API. It's well supported on Linux and Windows and the Direct State Access API makes it quite pleasant to work with (no more binding stuff). I though about using Vulkan but it would be a lot more hassle and when I made that decision there was no Mesa driver for nVidia hardware (I'm using an AMD GPU but I didn't want to close off that option). Mac only supports OpenGL 4.3, but I don't care about that system either.
UI scenarios
There are 2 dummy UI scenarios. Both look like crap because this isn't about the quality of font rendering, etc. I just wanted to get somewhat realistic lists of rectangles and textures.
sublime
scenario, 6400 rectangles with an average area of 519px². Mostly small glyph rectangles but also some larger ones (window, sidebar, etc.) that push up the average.
mediaplayer
scenario, 53 rects with an average area of 55037px². Not a lot of text, hence the bigger rectangles dominate.
Both scenarios are pretty extreme cases. sublime has a lot of small textured rectangles that show glyphs, meaning more load on vertex shaders. mediaplayer has a lot fewer rects where the larger ones really dominate, resulting in more load on fragment shaders. I figured most real UIs would be somewhere in between those two extremes.
Btw. that image in the mediaplayer is Clouds Battle by arsenixc. I just wanted something interesting to look at during development.
Measurement and benchmark procedure
From a measurement perspective each approach basically looks like this:
Benchmarked stages of the rendering process
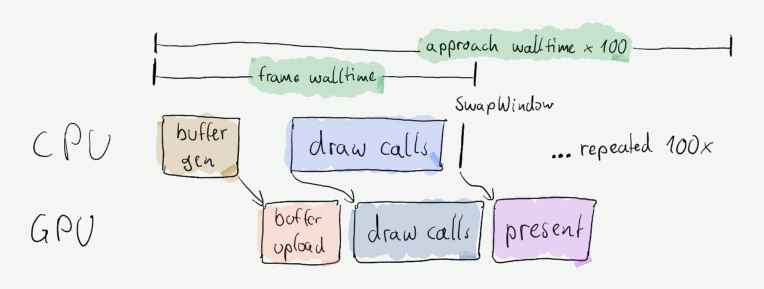
For each of those stages I measured different things:
- CPU walltime, measured with
gettimeofday().
- Consumed CPU time of the process, measured with
clock_gettime() (Linux) and GetProcessTimes() (Windows).
- GPU elapsed time, measured with
glBeginQuery(GL_TIME_ELAPSED, …) and glEndQuery(GL_TIME_ELAPSED).
- GPU timestamps with
glQueryCounter(…, GL_TIMESTAMP).
The GPU times are read after each frame so there is a pipeline stall there. I was to lazy to use multiple buffers for that. Also GL_TIME_ELAPSED timers seem to have a lot better resolution, so those in the benchmark results above. If something takes 100µs (that's thousands of a millisecond) it doesn't really matter, e.g. 111.200µs GL_TIMESTAMP vs. 107.680µs GL_TIME_ELAPSED. But for very short operations it can differ drastically: 3.840µs GL_TIMESTAMP vs. 0.640µs GL_TIME_ELAPSED. That was on a Radeon RX 480 on Linux (Mesa driver) and the Intel Arc A770 on Windows looks similar. On a GeForce GTX 1080 the difference wasn't quite so drastic (2.048µs GL_TIMESTAMP vs. 1.024µs GL_TIME_ELAPSED) but the resolution seems to be just a 10th of the other cards.
Measuring the consumed CPU time was a similar problem. That is the CPU time all threads in the entire process consumed. I wanted to know that to catch any processing that doesn't happen during the frame (driver overhead, pipelined drivers, etc.) and it's generally a nice indicator of how costly a given approach is on the CPU in total. Unfortunately on Windows the resolution of GetProcessTimes() isn't good enough to do that each frame. A lot of the values simply came out as 0 for most frames. Linux doesn't have that problem.
My workaround was to measure the walltime and consumed CPU time for 100 frames and divide it by 100. Unfortunately this includes the benchmarking code itself, which does some pretty hefty printf() calls to log the data. But that is the same overhead for all approaches. So if one approach consumes 40 times more CPU time than another (I kid you not) it's pretty inefficient, benchmarking overhead or not.
Dumping all that data into a bar chart would be useless, so the result charts only show the interesting measurements. Those are also depicted in the stage diagram above. And yet the result chars are still pretty unwieldy. :(
- Approach walltime (with overhead): The CPU walltime to render 100 frames with a given approach, including the time it took to measure and log the data. Then divided by 100 to get an average per-frame time.
- Approach CPU time (with overhead): Consumed CPU time of all threads in the process to render 100 frames. Again including the benchmarking overhead, again divided by 100.
- Frame CPU walltime: The CPU walltime from the start of the frame until after the call of
SDL_GL_SwapWindow(). Pretty much how long the CPU takes to tell the GPU what to do. This does not include the pipeline stall to read the GPU times (but maybe SDL_GL_SwapWindow() does a pipeline stall, I don't know).
- Buffer generation CPU walltime: Almost all approaches need to prepare one large buffer with all the rectangle data for the GPU. This is how long the CPU takes for only that stage.
- Buffer upload GPU elapsed time: GPU time spend to transfer the rectangle buffer from the CPU memory into GPU memory. Measured with
GL_TIME_ELAPSED.
- Draw calls CPU walltime: CPU walltime spend to call the OpenGL draw calls. Basically how expensive it is to tell the OpenGL driver what we want from it.
- Draw calls GPU elapsed time: GPU time spend actually executing those draw calls on the GPU. This is how expensive the operation actually is for the hardware. Measured with
GL_TIME_ELAPSED.
- Present GPU elapsed time: The GPU time spend in
SDL_GL_SwapWindow(), whatever that is. I hope it's just the driver handing off the rendered frame to the window manager or DWM. But I added it to catch drivers that defer some work into that stage. Not sure what to make of the measurements, though. On Linux it's pretty much nothing, on Windows it can sometimes take longer than the rectangle rendering itself.
The benchmark itself simply runs every approach, each one rendering 100 frames without vsync. The benchmark program is then run 5 times in a row. Sometimes it's just slower, maybe because the benchmark starts on an unlucky core or something. Hence the 5 repeats. The average of those 500 samples is then taken to get the per-frame values in the result charts. Except for "approach walltime" and "approach CPU time", there it's just an average of 5 values divided by 100.
Thanks to my brother we could run the benchmark on a lot of different systems. He has quite a lot of different hardware and that way I got data for the Intel Arc A770 GPU, older and newer nVidia GPUs and a lot of different AMD GPUs. :)
Approaches
Now we're on to the meat of the thing.
The approaches I implemented are a somewhat random mishmash of ideas. No all approaches do the same. Some just implement basic textured rectangles while others offer more complex rendering features (like signed distance fields, rounded corners, etc.). That was just my laziness and the observation that it doesn't make that much of an impact and my data is pretty noisy anyway. Remember, I'm doing that just for fun.
I'll compare most approaches to the one_ssbo_ext_one_sdf approach. That was the most promising one when I had the idea to normalize the data, so it became the reference point.
For details feel free to look into 26-bench-rect-drawing.c. Again, be warned, this is ugly code. ;)
1rect_1draw
One draw call per rectangle. The rectangle data is set via uniforms and no buffer is needed. But that approach it pretty much maximum API overhead personified. Doesn't make much sense, but I wanted to see how spectacular the fireball is. Implemented textured rectangles, colored glyphs and rounded rectangles with borders for that one.
In the mediaplayer scenario with it's 53 rects it doesn't really matter. It consumes a bit more "Draw calls CPU walltime" but that's it. This scenario performs similarly for pretty much all approaches, so from here on out I'll only talk about the sublime scenario.
That one has 6400 rects and this approach just dies, with frame CPU walltimes being 20x to almost 40x slower than one_ssbo_ext_one_sdf (but on one slow system it was just 2x slower). The draw calls CPU walltime explodes even more spectacularly, mostly being a few hundred times slower than one_ssbo_ext_one_sdf. Now that is API overhead. :D
To put it into somewhat real numbers, on my Radeon RX 480 Linux system this means the following (1rect_1draw vs. one_ssbo_ext_one_sdf):
Frame CPU walltime: 3.699ms vs. 0.095ms
Draw calls CPU walltime: 3.651ms vs. 0.004ms
Draw calls GPU elapsed time: 0.236ms vs. 0.142ms
complete_vbo
The simplest "classic" way to render rectangles with one large vertex buffer in OpenGL. Six vertices per rectangle (2 triangles, each 3 vertices) with the per-rectangle data duplicated in each vertex. A vertex array object (VAO) and vertex attributes are setup to feed the buffer into the vertex shader. Again implemented textured rectangles, colored glyphs and rounded rectangles with borders.
Buffer generation CPU walltime is mostly 3 to 4 times slower than one_ssbo_ext_one_sdf which is no surprise. It generates pretty much 6 times as much data because one_ssbo_ext_one_sdf just uses a list of rectangles instead of vertices. Frame CPU walltime is mostly 2x that of one_ssbo_ext_one_sdf.
And in numbers on my Radeon RX 480 Linux system (complete_vbo vs. one_ssbo_ext_one_sdf):
Frame CPU walltime: 0.340ms vs. 0.095ms
Buffer generation CPU walltime: 0.123ms vs 0.032ms
Draw calls CPU walltime: 0.004ms vs. 0.004ms
Draw calls GPU elapsed time: 0.254ms vs. 0.142ms
one_ssbo
That approach was inspired by how compute shaders read their input (a more "modern" approach). It uses one shader storage buffer object (SSBO) with a list of rectangle data. An empty VAO is setup without any vertex attributes, so no data is fed into the vertex shader by OpenGL. But each shader can access the SSBO. Then 6 vertex shaders per rectangle are spawned, each shader uses the gl_VertexID to calculate the index of the rectangle it belongs to, reads the rectangle data and puts itself on the proper screen position.
This bypasses the whole VAO and vertex attribute mess of the OpenGL API, which is nice. But on the flip side we can only read uints, floats, vec4s and stuff. Not single bytes. So we have to unpack 8bit values from 32bit (e.g. colors) via bitshifts and bitmasks or bitfieldExtract() or unpackUnorm4x8().
Again implemented textured rectangles, colored glyphs and rounded rectangles with borders.
This one is usually about as fast as one_ssbo_ext_one_sdf. Sometimes a bit faster, sometimes a bit slower. The draw calls GPU elapsed time is usually a bit on the faster side but one_ssbo_ext_one_sdf can do more complex rendering so this is to be expected.
On my Radeon RX 480 Linux system:
Frame CPU walltime: 0.084ms vs. 0.095ms
Buffer generation CPU walltime: 0.025ms vs 0.032ms
Draw calls CPU walltime: 0.004ms vs. 0.004ms
Draw calls GPU elapsed time: 0.137ms vs. 0.142ms
All in all a pretty robust approach. Works well and is fast on pretty much any system the benchmark was run on, but I hope you like bit twiddling and memory layouts. ;)
ssbo_instr_list
This approach also uses one SSBO to store the rectangle data. But what kind of processing the fragment shader should do is stored in a second "instruction list" SSBO. For example if you just want to render a glyph there would be one entry in the rect list and one glyph rendering instruction for that rect in the instruction list. If you want to render a rounded rect with two borders you can do that with 3 instructions.
This makes each entry in the rect list smaller since it doesn't need to contain the data for all possible rendering features. Each instruction was also packed into 64 bit, making them fairly small. But the primary idea behind that approach was flexibility. I added instructions for different kinds of signed distance fields (rounded rect, circle, lines, etc.) and wanted to combine them with border drawing, drop shadow drawing and so on. And you would only have to pay that memory and processing cost for rects that actually use those instructions. Again, inspired by how you would do it with compute shaders. Sounds nice, doesn't it?
The frame CPU walltime is mostly a bit faster than one_ssbo_ext_one_sdf. But for draw calls GPU elapsed time it depends. AMD mostly agrees with that approach. There the GPU time is roughly about as fast as one_ssbo_ext_one_sdf. Sometimes it just takes 0.6 times, sometimes 2.0 times as much GPU time. nVidia and Intel disagree. :( On nVidia it takes about 2.0 times as much GPU time, on Intel 3 to 4 times. Seems like they really don't like that the fragment shader reads a variable number of instructions, even if most rects just read one (glyph instruction).
On my Radeon RX 480 Linux system (funnily enough on Windows this approach was twice as fast):
Frame CPU walltime: 0.136ms vs. 0.095ms
Buffer generation CPU walltime: 0.019ms vs 0.032ms
Draw calls CPU walltime: 0.004ms vs. 0.004ms
Draw calls GPU elapsed time: 0.288ms vs. 0.142ms
So this approach offers great flexibility, seems to be about as fast as one_ssbo_ext_one_sdf from the CPUs point of view but stresses Intel and nVidia GPUs a lot more.
ssbo_inlined_instr_6
Well, what if we read those processing instructions in the vertex shader instead of the fragment shader? That way each rect would only read the instructions 6 times from GPU global memory (once for each vertex). Of course we then need to transfer those instructions from the vertex shaders to the fragment shaders. In this case I used an uvec2[6] array, aka 6 64 bit values. This limits the flexibility somewhat, but with 6 instructions you can do a lot of fancy stuff (e.g. drawing a rounded rect with 5 different borders).
AMD and Intel GPUs like it. For those it usually takes ~1.1 times (AMD) or ~1.5 times (Intel) as much GPU time as one_ssbo_ext_one_sdf. Still not great, but think about the flexibility those instructions allow! :) Well, nVidia just says no. They take 3 to 4 times as much GPU time. :(
At that point I was very tempted to just ignore nVidia GPUs. They have how knows how many engineers and enough marketing people to tell the world 10 times over how great their GPUs are. Then I should not have to worry about iterating over an instruction list in the fragment shader. Maybe it's the data transfer from vertex to fragment shader (but other approaches use more and are a lot faster), the bit unpacking in the fragment shader, maybe its just the instruction loop, I don't know. In case anyone has an idea feel free to look at the source code.
Then, grudgingly, my professional attitude came back in. I wanted to see what works well on every GPU… well, the instruction list doesn't. :(
one_ssbo_ext_one_sdf
This is basically back to one_ssbo but extended to support more fancy shapes within a rectangle. That works via signed distance functions to draw rounded rects, pie segments, polygons, etc. However it's limited to one fancy shape per rect, one border, etc. No more instruction list in there.
It works reasonable well on all GPUs, hence it became the reference point to compare the approaches.
On my Radeon RX 480 Linux system:
Frame CPU walltime: 0.095ms
Buffer generation CPU walltime: 0.032ms
Draw calls CPU walltime: 0.004ms
Draw calls GPU elapsed time: 0.142ms
inst_div
One last experiment. I hacked that one together pretty much as my brother was starting to run the benchmarks on various machines. :D
Anyway, its mostly the same code as one_ssbo_ext_one_sdf but the data is not read from an SSBO but instead fed into the vertex shader via vertex attributes and instancing. Back to the "classic" OpenGL style. The idea is to have two vertex buffers: A small one with just 6 vertices (1 rectangle) and a larger one with per-rectangle data. The small vertex buffer is then draw with instancing, one instance per rectangle. The larger vertex buffer is setup in the VAO to advance by 1 for each instance (aka an instance divisor of 1). This lets the OpenGL driver generate the buffer decoding shader code, which is hopefully more optimized than my stuff. The API functions to setup the VAO (what stuff in the buffers goes into what vertex shader attribute) can be a bit confusing but the Direct State Access API makes that tolerable.
Turns out the Intel Arc A770 really likes it. The GPU time goes down to 0.34x of one_ssbo_ext_one_sdf. On the GTX 1080 it's 0.67x. For the rest it's pretty much the same as one_ssbo_ext_one_sdf.
I'll probably use that approach in the end, even if it's less "modern". Simply because I don't have to write the whole bit unpacking stuff in the vertex shader and the VAO setup isn't that bad. At least as long as I use nice round types like 16 bit signed int coordinates. If I need to pack the data a bit tighter (e.g. 12 bit per coordinate) it's back to SSBOs and manual unpacking.
Quirks and closing remarks
I got sidetracked for way to long on this thing. But I guess it's nice to know how SSBOs and classical vertex attributes stack up against each other. Spoiler: It doesn't matter for this workload, use whatever floats your boat.
Another interesting aside was the difference between Linux and Windows OpenGL drivers. I'm using Linux and Windows on my Radeon RX 480 PC in a dual boot configuration (Linux for productive things, Windows for games or fooling around with the WinAPI… which is also like playing games). The result charts contain the benchmark on Linux and Windows, directly next to each other. So there's a direct comparison there. Some years ago the open source Mesa drivers had the reputation of being relatively slow. Doesn't look like it. They're basically just as fast as the Windows driver on my machine. Except for the 1rect_1draw approach. All that API overhead takes almost 3x as long on Linux. The benchmark also consumes a lot less CPU time on Linux but I have no idea what part of that is the OpenGL driver, window manager, just a more optimized printf() function or whatever.
During development I also looked at tooling. I've been using RenderDoc for a few years now and is pretty nice but it can't really tell you why a shader is slow. The Radeon GPU Profiler looks pretty neat, especially those instruction timings, but it only supports Vulkan and DirectX 12. If anyone knows such an shader instruction timing tool for OpenGL 4.5 please let me know. On the other hand that might be a reason to rewrite the thing in Vulkan in a few years.
I've omitted a lot of detail (like the different CPUs), but the post is already too long as it is. In case you have any questions feel free to drop a comment or send me a mail.
If you read the whole thing until here, color me impressed. Take a cookie, you deserve it. ;)
TLDR: Java is still a pain for me, but it can be a lot less than I used to belief.
Old prejudices
I usually try to avoid Java projects. In normal C code it's pretty easy to see what the machine really does and well written code (in most languages) can also communicate what the programmer meant to do. Both are important aspects of a program, especially when you have to debug it. But when reading Java code I mostly just get impressions of the kinds of diagrams people drew on whiteboards (or in their heads) or how their teams were structured… or of confusion.
There seems to be a lot of object orientation religion involved and no, you can't properly solve a problem by blindly throwing "design patterns" at it until the problem rage-quits. Understanding the problem itself is important. But this might just be because I mostly see Java code in academia or university. But the few commercial projects I've seen don't exactly inspire confidence in other areas. Java projects also seem to be rather fond of a lot of tooling but fortunately I wasn't to involved with that. It doesn't sound motivating to spend more time debugging skyscraper sized tooling stacks than to work on the actual problem.
I also have mixed feelings about the language design and API design of the standard library. I mostly get the point of what they were trying to achieve (making it simple enough so you can easily swap programmers, static exception handling, etc.) but I can't say I've ever seen most of that work out in real life. But then it hardly does for any language. And like any other language Java has some pretty nice parts as well. The way you can package your entire application into one JAR is nice and can make deployment very simple if you bother to care about it. So maybe my problem is mostly not with the language but maybe more with how the community uses it, I guess.
A more recent experience
Sorry for the short rant. Anyway, a while ago I stumbled into a Java codebase again. A friend of mine has to work with RDF and tripple stores and they're using Fuseki as a database server. You basically send a query via HTTP and get back the results. Neat and simple. Especially if you fetch the results as JSON-LD which also does some post-processing to make the data almost human readable (the so called compacted form). But in our case we needed to do some further processing of the data and that post-processing made it a lot more complicated. So I wanted to disable it (get the so called "expanded" form).
Jena (the library behind Fuseki) supports that exact output format. At least the functionality is in their API docs. How about a quick patch for Fuseki to add that output format? How hard can it be, right? Even with content negotiation, which isn't all that complicated when you get down to it. Just add another mapping of the expanded JSON-LD content type to the corresponding Jena output format. Or another if statement or a branch in a switch case statement. Something like that. Probably.
I gave up after a couple of hours. To me it looked like a horrible mess of interconnected classes for even the simplest of tasks. Abstractions that don't make stuff simpler but mostly create confusion and limit what you can do. But the whole ordeal got me thinking: Do you have to program in Java that way?
Java changed over the years
A few weeks later and pretty much by accident I ended up skimming through the list of JDK Enhancement Proposals (by JDK version, full list). Most languages have stuff like that and for me it was a convenient way to see what changed over the years. Without all that marketing bullshit or oversimplification that most normal online articles do.
And there is a lot of interesting stuff there:
JEP 222: jshell: The Java Shell (Read-Eval-Print Loop)
Basically an interactive console like irb, php -a, python, node, etc. Nice to test out API details and do some exploration. Worked quite well for me and not something I expected to see with Javas heavy focus on compilation.
JEP 286: Local-Variable Type Inference
Again common in other languages like C++ or D (there it's auto instead of var). For me this made a big impact. In my personal just-for-fun projects I like to avoid large IDEs or complicated tooling. There are various reasons for this but this is a discussion for another time. With Java this was a problem since I had to lookup return types in the documentation. Not anymore. :) To me it makes longer code a lot less cluttered as well. And when the type of a variable is important to the reader you can just write it explicitly without var.
Here is an JDBC example I had to write up a while ago:
// Run with: java -classpath sqlite-jdbc.jar:. Sqlite.java
class Sqlite {
public static void main(String[] args) throws java.sql.SQLException {
try (var con = java.sql.DriverManager.getConnection("jdbc:sqlite:data.db", null, null)) {
try (var stmt = con.prepareStatement("SELECT id, body FROM posts")) {
var resultset = stmt.executeQuery();
while( resultset.next() ) {
System.out.print(resultset.getInt("id") + ": ");
System.out.println(resultset.getString("body"));
}
}
}
}
}
var makes this kind of thing a lot more convenient to write for me. Sorry for the missing syntax highlighting. I don't bother with it here.
JEP 330: Launch Single-File Source-Code Programs
Single source file programs can just be executed via java Sqlite.java. No need to compile it first. You could always do javac Sqlite.java && java Sqlite but this brings it more in line with scripting languages. Neat for fast prototyping and small experiments.
JEP 408: Simple Web Server
Again something nice but mostly because it pointed me to the com.sun.net.httpserver package of the standard library and this StackOverflow answer. Turns out you can write a small scale HTTP server in Java perfectly fine without needing to go through all that Servlet hassle:
// Run with: java MiniHTTPServer.java
import com.sun.net.httpserver.*;
import java.nio.file.*;
import static java.nio.charset.StandardCharsets.UTF_8;
class MiniHTTPServer {
public static void main(String[] args) throws java.io.IOException {
var server = HttpServer.create(new java.net.InetSocketAddress("localhost", 8080), 0);
server.createContext("/", con -> {
con.getResponseHeaders().set("Content-Type", "text/html; charset=UTF-8");
con.sendResponseHeaders(200, 0);
var out = con.getResponseBody();
out.write("Hello World!".getBytes(UTF_8));
out.close();
});
server.createContext("/file", con -> {
con.getResponseHeaders().set("Content-Type", "text/html; charset=UTF-8");
con.sendResponseHeaders(200, 0);
Files.copy(Path.of("some_file.html"), con.getResponseBody());
con.close();
});
server.start();
}
}
The nice thing is it's all part of the standard library, no dependencies required. I really like that since I try to avoid needless dependencies in my projects. Pretty much the opposite of "modern" web development in some respects. :D
Of course there are a lot of other features like Switch expressions, Text Blocks and Records but the stuff above was the most relevant to my style of doing a lot of small iterative experiments.
Playing around with Jena
The final stretch of my Java just-for-fun weekend was working with Jena. Basically I wanted to write a small HTTP server that executes SPARQL construct queries and returns the result as expanded JSON-LD.
Turns out it's just about 90 lines of code. That includes a small HTML page to enter the SPARQL query, a bit of JavaScript to send the query as JSON and a small example construct query. All within a text block. I didn't put it on GitHub because, well, it's just one file. The JSON stuff is mostly there because I wanted to test out JSON parsing in Java. Unfortunately I didn't find a way to do it with the standard library but Jena provides an API for that anyway.
Given, I had to manually download Jena and used their JavaDoc quite a bit. But all of that without any big IDE, Maven and all that. Just with some text editor (Sublime Text in this case) and browsing the API docs. Which are funnily enough easier to work with than the endless prose of the Python documentation.
For seasoned Java developers this might seem a bit weird but I work on a lot of different projects in a lot of different languages and contexts. From Assembly to PHP, Ruby, JavaScript, C, GLSL and what not. So I usually stick to the basics and don't spend much time with specialized tooling that needs regular tending (like IDEs or complex tool stacks). Pros and cons, as always.
Well, that was a fun little exploration weekend. The Java eco-system is still not something I enjoy working with but the language itself isn't too bad. It came a long way in the last 10 years or so since I actively started avoiding it. Who knows, maybe it will be a good fit for some future project. :)
I've spend the last couple of days tinkering around at a process visualization tool.
It shows the virtual memory of a process on a 2D map and threads as small dots jumping around (at the instructions they're executing).
The map also shows the public symbols within a given shared library (e.g. poll() in libc). Just to give you an idea where threads are hanging out.
Visualizing a media player process. Looks like threads are sticking around libavcodec, poll(), pthread_cond_wait() and a few other places.
If you want to try for yourself you can get the code at github. But it's a linux-only tool and you'll have to compile it yourself.
The main purpose of the tools is to give students an easier and intuitive idea of what a process is. It's not a serious debugging tool something like that.
I've had the idea while I was still giving the operating system lecture at university.
Back then I saw the xkcd Map of the Internet, and poof, stuff happens in your head and you can't unthink the idea.
That was quite some time ago but it was a nice pretext to fiddle around with raylib and ptrace.
Thanks to Chris from bedroomcoders.co.uk for giving me the final push to try out raylib. It really is a nice library to work with.
Aside from raylib the project had other interesting aspects:
Hilbert curve:
This is a nice way of mapping the 1D address space of a process onto a 2D map.
Quite a neat idea but for now the mathematical details are beyond me. Maybe in the future I'll find the time to derive the largest
completely enclosed 2D rectangle for a given 1D range on a Hilbert curve. That would be rather neat to properly position
the labels of address ranges or the linker symbols in them. But who knows when that fancy will strike me.
ptrace was another Linux API I wanted to try for a while now.
It's basically the Linux API for debuggers like gdb and to be honest that kind of shines through.
I probably abused the API for what I did here. :D
ELF dynamic linker symbols and DWARF debug symbols: Here we are again in fantasy land. Where I write this on something
that was formerly called the GNOME 2 desktop (now MATE). Some fantasy authors would have been proud.
Anyway, I wanted to put at least some functions on the map. Primarily to see whats inside address ranges that contain executable code.
While not simple ELF is straight forward enough to read the dynamic linking symbols from its .dynsym section. And those have to be there for every shared library.
Also showing DWARF debug symbols would have been nice. But unfortunately this got a bit to complex for a just-for-fun operation.
And getting debug symbols for e.g. Debian packages is kinda complicated (how to load them is nicely documented though).
Well, maybe some other time. :)
I hope someone else finds this tool illuminating or at least helpful. :)
If anyone is interested I can explain stuff in more detail. For example how one texture is used to draw the map regions and borders without polygons
(plus one texture for each address region with symbols in it). I'm just to lazy to go into details if nobody is interested. :D
A friend of mine recently worked on a search for a system that used a triplestore.
The problem was a simple one: Find all the stuff with a given string in it, even if the string isn't a whole word.
They ended up with about 5 million (id, text) pairs, used Elasticsearch and the queries are usually faster than 1 second.
I don't know the details of what else is going on (ranking, sorting, etc.) so please don't take this a representative performance of Elasticsearch. ;)
But I asked myself:
How fast would that be if we brute-force it with grep?
What if we write all the (id, text) pairs out to a file, one pair per line.
Then use the grep command line program to get all lines that contain a specific substring.
And from those matching lines we can extract the IDs. A few lines should do the trick, right?
For how much data would this be a good sweet spot of complexity vs. performance (read: The right tool for the job)?
So I wrote a microbenchmark. Because what else do you do over Christmas? :)
In case you couldn't tell already: This is going to be something only programmers can obsess over. You have been warned. ;)
The overview
Just in case you only want the gist of it and don't care about the details:
- Tested a file with 10 million lines (1.4 GiByte), each line about 150 bytes. Also tested a few other sizes but the performance didn't change much.
- The tests were run on a notebook with an Intel i7-8550U @1.80GHz with 32 GByte RAM running Linux 5.3.0
- The entire file fits into memory (is kept in the kernel page cache) so we don't have to wait for the SSD to read the data.
Now on to the data itself:
Searching for a string in a line with different tools and languages

grep can handle 2.3 GiByte/s. If you have just 1 million searchable records, each about 150 bytes long that would be about 145 MiByte of data.
grep will chew through that in about 63ms. Pretty fast, isn't it?sed, awk and mawk are slower, but still pretty fast.
I wanted to know how fast a naive implementation of a search would be in different languages.
Please don't take this as a performance comparison.
There are many different reasons to choose a language for a project, and performance of the language itself usually isn't a terribly important one.
I usually work with different languages at the same time (use the right tool for the job) and I wanted to know what performance I can expect in a given environment. :)
- The PHP, Python and Ruby programs that search each line individually are somewhat slower. But still in the hundreds of MiBytes/s on the test system.
- The last tree programs load the entire file into one string (e.g. with
mmap) and search it for matches. This eliminates the line iteration overhead.
A little more complicated but quite a bit faster.
If a search can take 1 second you can chew through about 1 GiByte of data in that time.
I also wrote a C programs that do the same as above.
And since multi-threadding in C is easier than in many interpreted languages I threw some threads at the problem.
Note the different scale.
C programs to search for a string in a line, including multi-threadding. Added grep for comparison.

- C can chew through a lot of data per second. :)
- But honestly I don't think I'll have a project anytime soon where I would sacrifice several GiByte of RAM just to keep a search index (the text file) in memory.
And as soon as the search index isn't in memory the search will be only as fast as the disk can provide the data (1.64 GiByte/s on the test systems SSD).
Note that the Linux kernel only keeps the search index in memory (in the page cache) if there is nothing more useful it could do with the RAM.
If nobody uses the search the kernel won't waste memory for it.
So much for the "short" version. If you're still interested in the details feel free to read on. :)
The test setup
All the programs, scripts and commands used are available in a GitHub repository.
I also put the raw benchmark results in there
(this includes the versions of everything used.
The benchmarks were run with the command ./bench.sh > debug.log 2> results.txt.
To get a reproducible data set I wrote a small ruby script to generate id: text lines.
The script uses a fixed seed so it always generates the same lines. A small sample:
http://example.com/3073701/Ybyld6r9vNai95TYXiQH4FuQV+l/CHMwP4i3jQ== qO76BFQLlj2g
http://example.com/3874850/zjQdPR3iPXe/f28d0x6D2fQONt8x j5gSmB0dQhRpZ5yjnMBU9la1Dl00wzcD2C7J
http://example.com/4659995/zLtSsvjmP6o6vYwQQm0VRTtgxM0xUbY= QvzHvFPq7/VrKDJbjoQ9xnzgUUEHP2F/RW2WbIOfnq0wgS5xNCCwF4w=
http://example.com/9674460/OGuKOpNt22+aPUfoW3XTBDOfh/q/lc8ysJpil+M= WURbI/R069glGkYLjfOizaobX5gJRUjF71pe
Pretty much base64 encoded random garbage.
Each line is on average about 150 bytes long, some a lot longer, some a lot shorter.
The 150 byte length doesn't have any deeper meaning. I just picked something.
You might have way fewer documents with a lot more text in them or way more things with just short text.
That's why I give the performance in MiByte/s. It doesn't matter that way.
| lines-100k.txt | 14.4 MiByte |
| lines-1m.txt | 144.9 MiByte |
| lines-10m.txt | 1.4 GiByte |
| lines-50m.txt | 7.2 GiByte |
| lines-100m.txt | 14.3 GiByte |
I generated a few of those files with 100 thousand, 1, 10, 50 and 100 million lines. Just to see if the programs would
behave differently.
The last step was to pick some substring in those lines (e.g. "VrKDJbjoQ9xnzg") and searched for it with different tools.
Each program was executed multiple times and the results were averaged. From 10 times for the small files like lines-1m.txt down to 2 times for lines-100m.txt.
You can look at bench.sh for the details.
Just like grep each tool is supposed to search a text file for lines that contain the given substring.
No matter where it is or if it's an entire word or just part of a word.
I just tested the tools I had already installed and what struck my fancy.
So don't be surprised if it doesn't include your favorite tool.
I also wanted to know how fast naive implementations of such a search would be in different languages.
That's how the PHP, Ruby, Python and C programs found their way into the benchmark.
Again, not to compare performance but rather to know what to expect in a given environment.
Measuring execution time
/usr/bin/time was used to measure how long it took for a program to go through an entire file (logged the wall time and some other stuff).
This isn't the time builtin of shells like bash or zsh but an extra program.
A small caveat here: The time program only reports times with 10ms precision (e.g. 0.21s).
Therefore I didn't do runs with 100k lines. Some programs were simply to fast and I got division
by zero errors. And I was to lazy to look for a tool to properly read the timing information form
the Linux kernel or write a skript for it.
All that stuff is available under /proc/[pid] in stat, io, smaps and more, see the proc man page.
The test systems
Two systems had the honor of not running fast enough when I had the idea for the benchmark.
So they had to search text files for substrings for the next two days. :)
One PC (can't blame it, it can't run):
Linux 4.15.0-91-generic #92-Ubuntu SMP x86_64
CPU: Intel(R) Core(TM) i5-3570K CPU @ 3.40GHz
RAM: 15.6 GiByte
Memory bandwith: 15.96 GiByte/s (reported by `mbw 2048`)
Disk: 4TB WD Red "WDC WD40EFRX-68WT0N0 (82.00A82)"
Read speed: 103 MiByte/s (measured with `wc -l`)
And one notebook (no excuses here):
Linux 5.3.0-46-generic #38~18.04.1-Ubuntu SMP x86_64
CPU: Intel(R) Core(TM) i7-8550U CPU @ 1.80GHz
RAM: 31.1 GiByte
Memory bandwith: 13.8 GiByte/s (reported by `mbw 2048`)
SSD: 1 TB Samsung "MZVLB1T0HALR-000L7"
Read speed: 1.64 GiByte/s (measured with `wc -l`)
The rest of the article only shows the results of the lines-10m.txt run (10 million lines, 1.4 GiByte) on the notebook.
It's pretty representative of the other runs. No need to show more data that doesn't say anything interesting.
Funnily enough both CPUs performed pretty much the same. Well, the task at hand isn't exactly black magic, even for older CPUs.
Anyway, the full data of all runs is in the repository.
Assumption: All the data fits into memory
Or rather in the page cache. In case this is new for you:
When you read data from a file the operating system does something nifty.
If it has unused memory left it keeps the data in there.
The next time a program wants to read the same chunk ("page") of the same file the operating system takes it right out of the page cache.
That way it doesn't have to wait for the disk again to get the data.
Well, free memory doesn't help anyone, so might as well use it to cache some data that might help someone in the future. :)
In the benchmarks below I read the file once with wc -l.
From then on it's in the page cache and all consecutive programs got their data straigt from there.
Thanks to that the benchmarks are not bound by the read performance of the disk.
As long as the file fits into the page cache that is.
If the file is for example larger than the memory your program is always limited by how fast your disk
can provide data (e.g. 1.64 GiByte/s on the notebooks SSD).
Results and findings
Ok, that's it for the "preliminaries". Now on to the real meat: The results and what suprised me.
Funny thing: grep is faster with longer search strings
While testing out grep I noticed that longer search strings seem to perform better:
Searching for substrings of a different length with grep.

Here are the individual commans:
short, 2310 MiByte/s:
$ grep VrKDJbjoQ9xnzg lines-10m.txt
medium, 4177 MiByte/s:
$ grep V6TGqGjjnmhlHRcYEq1IJCgzUNSx09bCkwJnEK lines-10m.txt
long, 5207 MiByte/s:
$ grep FMzaoLmVeEoJ3PAPERDFSO2RFEo5/mO17YTQrXz4jr0Ud9w0854q6/rcRu11AocX3vzl4q7O0f6c lines-10m.txt
At first I was a bit startled by that.
Especially given that grep doesn't only search for simple substrings but can also search for regular expressions.
But then I realized that the longer the match the smaller the characters in a line where the match could start.
In other words: If we search for a string that is 20 chars long we can skip the last 19 chars in each line.
They can't possibly contain a match. At least that's what I think is happening here.
This might also be a general optimization for regular expressions in grep. I haven't looked into it.
Update 2020-12-30: It's probably the Boyer–Moore string-search algorithm.
Forgot about that one. :D
In the rest of the article I quoted the performance for the smallest substring.
In my experience long substring searches are somewhat rare. But in the end that depends on your usecase.
The awk side of things
I also wanted to test out awk a bit.
If you've never heard about it: awk is a command line tool for line based processing.
Perfect for processing logs, CSVs, statistics and stuff like that.
It basically executes scripted actions before processing a file, then on each line that matches a pattern and after processing a file.
It can do much more than just search each line for a substring.
And what's really cool: awk reads the input line by line.
It doesn't have to load the entire file into memory.
So you can happily crunch gigabytes or terabytes of data all day long without worying about running out of memory.
Well, not that this is reflected in the benchmark since the entire file was in memory when those benchmarks were run. :P
I threw sed into the chart as well because it had no where else to go and felt lonely.
Searching for substrings with awk and sed.

GNU awk seems to be the default version, at least on Ubunt based systems.
The performance is pretty decent and it could handle about 350 MiByte/s on the test system.
mawk is another implementation and uses a bytecode interpreter.
I had it flagged down for a while because it seemed to be quite a bit faster than GNU awk.
Looks like it actually is. :)
Also kind of funny: When I used the index() function of mawk to look for a substring instead
of a regular expression it got quite a bit slower (the "mawk index" bar).
Naive line-by-line search in different languages
As mentioned before: I wanted to know what performance I can expect from a naive line-by-line search in different languages.
This might be useful to decide if I go with a simple low-effort brute-force solution.
Or if I have to spend a bit more time on evaluating alternatives (a database, library or whatever).
It all depends on the requirements and environment of a project.
The performance numbers given here are just datapoints that help to figure out how long a simple brute-force line-by-line search is fast enough.
Again: Please don't take this as a performance comparison. Because the world isn't that simple.
I hope you don't choose the programming language you use for a project based on it's naive find-substring-in-line performance. ;)
With all that out of the way, on to the programs. The code is simple enough, here for example in Ruby:
File.open(filename) do |f|
f.each_line do |line|
puts line if line.include? search_term
end
end
Searching for substrings line-by-line in PHP, Python and Ruby.

I wrote the same in PHP, Python and C as well. But we'll look at the C programs later.
The nice thing of this approach is that we only need the memory for one line at a time.
No matter how large the entire file is we won't run out of memory.
As long as the entire file isn't just one big line that is. :D
Pretty decent performance for just a few lines of code.
Probably fast enough for a few hundred MiBytes of data.
But for larger data sets I would probably execute a grep command if the code only needs to run on Linux.
Search the whole file instead of each line
While playing around with the strstr() function in C I noticed that the function by itself pretty darn fast.
So wouldn't it be great if we could eliminate the line-iteration overhead and our code could spend all its time in strstr()?
What if we had the entire file in a single string.
Then we could search this one large string with consecutive strstr() calls until we've found all the matches and reached the end of the string.
This is more like searching in a file with a text editor than searching each line individually.
Each time we find a match we could search for the start and end of the current line and print the entire line (just like grep does).
Then our code wouldn't have to loop over each line, wasting instructions and CPU time doing so.
Might be faster but it would no longer be easy to search for multiple substrings in the same line.
Also the code is more complicated than before, e.g. see ruby2-all-index.rb.
Another slight problem is that we would need the entire contents of the text file in one huge string variable to do that.
But reading several hundred MiBytes kind of sucks: We would go over the entire file just to load it into memory and then go over that memory again to search it.
Well, somewhat obscure (depending on your background) operating system knowledge to the rescue! :)
Operating systems can "map" files into memory.
Basically the operating system reserves a part of your memory (address space to be more exact) that is as large as the target file.
When you access that memory at a given place the operating system automatically reads the corresponding chunk of data directly from the file.
Meaning you can read data from a file just by looking at the right memory address.
And big surprise: A string is just another (usually small) part of your memory.
So with memory mapping we can use the entire file as one large string without having to read it first.
The operating system reads the parts that are used as soon as we access them.
There's more to memory maps than that.
For example the operating system can easily evict seldomly used data chunks and use the memory for more important purposes.
If need be it can always read the data chunks from the disk again.
This can be useful when some other programs quickly need more memory (e.g. when you open a particularly "modern" website in your browser).
Anyway, I gave it a spin and lo and behold now we're talking. :)
Searching for substrings in one big mmaped string in PHP, Python and Ruby.

PHP and Ruby really shift up a gear here. Easily achieving several times their previous performance.
Depending on the usecase this might be complexity well invested.
Python is pretty interesting here: It has an explicit mmap() function that maps a file into memory.
The 2nd Python program uses that but otherwise does a line-by-line search just as before.
Just with that it's a bit faster, but this is probably not because of the memory mapping itself.
Usually reading lines from a file in Python returns an str for each line.
Those are encoding-aware and might do some extra stuff for that.
Reading lines from a memory mapped file tough returns bytes. Those are just raw data without any encoding.
When adding mmap() I also changed the search from str to bytes and I suspect that this causes the difference in processing speed.
Another note about PHP and Ruby:
Both languages don't expose an explicit way to memory map a file.
Of course there are extensions for that but I wanted to keep it simple.
Instead they both have functions to read the entire file into a string (file_get_contents() and File.read()).
I hoped those use the C function fopen() internally because that in turn uses mmap() and maps the file into memory instead of reading it chunk by chunk.
This worked out in my micro-benchmark here but I wouldn't count on that behaviour for a real project without further research.
Especially if the file is larger than the systems memory. ;)
Going faster - C and multithreading
It might suprise some people but I still write quite a bit of code in C.
Some tasks are simply easier done there than in other languages.
Naturally I also wanted to know how fast the above programs would be when written in C.
Oddly enough threadding is something I find way easier in C than e.g. in Python or Ruby.
No need to worry about the global interpreter lock (aka GIL), garbage collector and so on.
We just let each thread search a slice of the data, e.g. 4 slices for 4 threads.
All previous benchmark results were still quite a bit away from the systems memory bandwith of 13.8 GiByte/s (as reported by mbw 2048).
That is a very rough estimate of how fast the CPU can read from and write to RAM.
Maybe multithreadding will help us getting closer to that limit.
Sorry, unfortunately the sky isn't the limit for a CPU. :P
Searching for substrings with C: Line-by-line, in one big mmaped string and multithreaded. Added grep for scale (sorry, no bananas here).
Well, it turns out that i7-8550U can read more than 13.8 GiByte/s. :D Incidently the PC system peaked at 4 threads with 16.8 GiByte/s.
Turns out that if you really need performany C is the way to go. By a wide margin.
With 4 threads the test system could search through 1 GiByte of data in just 65ms.
I've seen a lot of SQL queries that operated on a lot less data and took a lot longer.
But if that makes sense depends on your project and environment (as usual).
The downside is the complexity of the task in C.
You have to be careful to properly slice the data and how to put a zero-terminator at the end of each slice (strstr() needs one).
Not as easy as writing a hand full of lines in Ruby. But not particularly difficult if you're fit in C.
You can look at c5-threaded-strstr.c for more details or feel free to just ask.
Putting the pedal to the metal
Ok, I didn't.
To utilize the maximum memory bandwith of modern CPUs you have to use vector instructions to fetch data from memory into vector registers.
Not to mention that we can use vector instructions to scan a lot of characters in parallel.
More details about that (and much more) are in Agner's optimization manuals.
But a fair bit of warning, this is pretty advanced and detailed stuff over there. ;)
As much fun as it would be to write an AVX2 assembler version my motivation didn't cary me that far… yet.
Honestly I can envision myself using and maintaining the multithreaded C version in some circumstances.
But an AVX2 version… not very much. But well, who knows what the future will bring. :D
When the data is a tight fit
In all previous runs the entire data easily fit into memory.
I wanted to see how far I could take this until we get limited by the read bandwith of the drive on which the file is stored.
My PC has 15.6 GiByte RAM (as reported by the free program), so I did a run on it with 100 million lines (14.3 GiByte).
I didn't use the notebook because I was to lazy to generate a 31 GiByte test file. :P
This run only contains some of the programs that can handle files that are larger than the memory.
Either by iterating line-by-line or by explicitly memory mapping the file.
While all the data might still fit into memory I didn't want to risk thrashing.
Searching a 14.3 GiByte file on a PC with 15.6 GiByte RAM and 104 MiByte/s disk read speed.

grep and the search-by-line C program are straight out limited by the read speed of the disk (104 MiByte/s).
Where we previously had hundreds of MiByte/s or even several GiByte/s we're now down to whatever the disk can provide.
Remember, this one chart shows benchmark results from the PC.
There the file was stored a HDD (104 MiByte/s), not an SSD like on the notebook (1.64 GiByte/s).
It starts to get interesting when the first program runs that explicitly uses memory mapping.
The first time it still reads the entire data from disk.
But after that it and all the following programs (also using memory mapping) get the data from the page cache.
I'm not sure why that is. But given that this is a corner case I didn't dig any deeper.
I can't really see myself wanting to use pretty much all of my memory as a cache for a substring search. ;)
A bit of perspective
As much fun as it is to optimize the brute-force approach… at some point it will no longer be the right tool to solve the problem.
If your data is just a few MiBytes in size, or even a few hundred MiBytes, the brute-force appraoch is quite attractive.
You only need to write the file with all the data and execute a grep command when someone does a seach.
All in all just a few lines of code.
Pretty nice complexity to performance ratio I think :)
Personally pretty much all the projects I did for customers were in that category (e.g. entire database SQL dump of a few hundred MiBytes).
So for me those performance numbers are actually kind of relevant. :o
But sometimes you have a lot more data, and at some point brute-force just isn't viable anymore.
Either because the text file gets to large or you don't want to waste the memory and I/O bandwidth.
For those situations other tools are better suited to get the job done.
Databases have indices for a reason (but I don't know a good index structure for substring search).
In that situation my first approach would be:
Maintain a list of unique words in the searchable data.
Use that for an autocomplete on the client side so the server only ever gets full words (not substrings).
Then use a word based search on the server (a simple Python dict lookup or a hash table, a text index in SQL, Elasticsearch, whatever).
But again: Only if the naive approach would be to slow or large.
After all a dozzen lines of code are quickly thrown away.
And sometimes the naive approach might carray you further than you think.
In the end it isn't about which solution is the "best", but instead about which solution is a better fit for a given problem in a specific environment.
And I hope this blog post at least somewhat hinted at the boundries of the brute-force search method.
That it showed the complexity-to-performance sweet spot for this approach: When it can be used and when it stops being useful.
If anyone is reading this far: Wow, I'm amazed at your endurence. Take a cookie and enjoy the holidays. :)
A while ago I wanted to plot a simple mathematical function for a project of mine. No problem, there are a lot of good
function plotters out there. Then I stumbled over the polynomial smooth min function by Inigo Quilez. It
was written for GLSL shaders so it uses functions like clamp() and mix():
float smin( float a, float b, float k )
{
float h = clamp( 0.5+0.5*(b-a)/k, 0.0, 1.0 );
return mix( b, a, h ) - k*h*(1.0-h);
}
Ok, getting that into one of those plotters seemed like a hassle. Some of those tools can do amazing things, but I’m a
programmer so I wanted to write the functions in some programming language. I found code snippets and small
libraries to draw function plots into a canvas but nothing simple with panning and zooming. I know there’s insert your
favorite tool here but my Google bubble wasn’t trained for that and I didn’t find it. Of course there are the
heavy-weights like Octave or CindyJS but those didn’t
appeal to me at all.
I think you can guess the rest. :D How hard can it be to write a simple plotter with panning and zooming? So I wrote a
little tool for my own personal needs: js2plot (GitHub project).
It executes a piece of JavaScript and in there you can call plot() to show the graph of the function. You can then
explore the graph with panning and zooming. Or add more functions, or use variables, JavaScripts Math functions, and
so on. All in all nothing special but for me it’s more convenient to write mathematical code that way (see smooth min
example).
In case that you have the same problem I hope the tool is useful to you. The plotting part is written as a small
library without dependencies. With it you can turn a canvas element into a graph with panning and zooming. But you
have to provide a way for users to write the plotting code.
ps.: I only use the tool on desktops and notebooks so I didn’t implement touch panning and zooming. Panning isn’t a
problem but handling to a pinch-zoom still seems like a pain. Reimplementing that gesture isn’t my idea of fun so I
skipped it for now.
A few days ago I implemented a style switcher for my latest project. Unfortunately I ran into a rather obscure Chromium (and WebKit) bug. This post should give a small heads up to anyone running into the same weird effects. I opened an issue for the bug, so please post your comments there.
To switch between styles you just have to disable the current stylesheet and enable another one. I had no trouble with that in Firefox and Internet Explorer. But in Chromium and WebKit enabling the other stylesheet doesn't work the first time. It just stays disabled. This leaves the page unstyled since the first stylesheet gets disabled (disabling works). The bug only happens the first time. When you disable it and enable it again it works.
And that’s also the workaround: Instead of just enabling the other stylesheet you can enable it, disable it and then enable it again. All in one go.
Time to illustrate this with some code. This is the code of a small page usually styled by blue.css. As soon as the page is loaded the style is switched to green.css:
<!DOCTYPE html>
<title>Switch when loaded</title>
<link href="blue.css" rel="stylesheet" title="blue">
<link href="green.css" rel="alternate stylesheet" title="green">
<script>
window.addEventListener("load", function(){
var blue_style = document.querySelector("link[title=blue]");
var green_style = document.querySelector("link[title=green]");
blue_style.disabled = true;
green_style.disabled = false;
});
</script>
…
Note that green.css is an alternate stylesheet, meaning it’s not used by default (the browser ignores it). When the page is loaded the styles’ disabled attributes are set accordingly. That attribute is part of the HTMLLinkElement interface. Or you can use the newer StyleSheet interface in which case it would be green_style.sheet.disabled = false; (same bug applies).
The workaround looks rather silly but is effective never the less:
<!DOCTYPE html>
<title>Switch when loaded</title>
<link href="blue.css" rel="stylesheet" title="blue">
<link href="green.css" rel="alternate stylesheet" title="green">
<script>
window.addEventListener("load", function(){
var blue_style = document.querySelector("link[title=blue]");
var green_style = document.querySelector("link[title=green]");
blue_style.disabled = true;
green_style.disabled = false;
// Workaround for Chromium and WebKit bug (Chromium issue 843887)
green_style.disabled = true;
green_style.disabled = false;
});
</script>
…
You can try it with this minimalistic standalone style swticher. The styles just change the color of the first paragraph. When it’s black the page is unstyled. This only happens when you load the page and click on "green". Everything else after that or every other combination of clicks works.
Finding the cause of the bug was quite maddening… and I hope this post spares you the same experience.
A few years ago I wrote a small PHP function to send mails via SMTP. Not so long ago a friend asked for it. So I cleaned it up and wrote a bit of documentation: smtp_send. It won’t work for everyone but it’s only about 90 lines of code and you can easily change it to suite your needs.
If you don’t care about dependencies or code footprint you can use one of the many libraries out there. But if you’re tired of PHPs mail() function, overly complicated APIs or huge amounts of dependencies just to send mails this might be worth a look. The function is meant for people who want to construct the mails themselves. Either for simplicity or because of more complex cases. Then you can use the function to simply send the result.
Usage example:
$message = <<<EOD
From: "Mr. Sender" <sender@dep1.example.com>
To: "Mr. Receiver" <receiver@dep2.example.com>
Subject: SMTP Test
Date: Thu, 21 Dec 2017 16:01:07 +0200
Content-Type: text/plain; charset=utf-8
Hello there. Just a small test. 😊
End of message.
EOD;
smtp_send('sender@dep1.example.com', 'receiver@dep2.example.com', $message,
'mail.dep1.example.com', 587,
array('user' => 'sender', 'pass' => 'secret')
);
I put it online because my friend searched for a simple PHP mailer but couldn’t find one matching the projects requirements. I had the same experience a few years ago. In the end decided to look at the SMTP RFC and write my own little function. With a bit of luck this makes your life easier if you’re caught in same corner cases.
The documentation also contains examples of mails with attachments, alternative content (HTML mail with plain text fallback) or both (alternative content nested in mixed content). For some reason this information seems to be surprisingly hard to find.
Thanks for scrolling down all the way, it can get quite lonely here…
Anyway, looking for older entries? Want to know more? Take a look at the archive.